MÀSTER DE LOGÍSTICA TRANSPORT I MOBILITAT (UPC) CURS 0708
DIPLOMATURA D’ESTADÍSTICA
MÀSTER DE LOGÍSTICA, TRANSPORT I MOBILITAT (UPC).
CURS 07-08 Q1 – EXAMEN FINAL ORDINARI
Mètodes de Captació, Anàlisi y Interpretació de Dades .
(Data: 17/1/2008 16:00-19:00 h Lloc: Aula H-9.2 CS)
|
Nom de l’alumne: |
|
Professor responsable: Lídia Montero Mercadé
Localització: Edifici C5 D217 – Campus Nord
Normativa: NO ES PERMÉS DE DUR LOS APUNTS PUBLICATS
SI TAULES ESTADÍSTIQUES
ES POT DUR CALCULADORA y FORMULARI OFICIAL
Durada de l’examen: 3h 00 min
Sortida de notes: Abans 21/1/2008 al WEB de l’assignatura.
Revisió: El 21/1/2008 a las 15:00 hores (C5-217 Campus Nord).
Puntuació sobre 20 – 1 Punt per Apartat
DASL, Data and Story Library del Carnegie Mellon, dispone para un conjunto de 23 países de datos relativos a su tasa de inflación anual, dos indicadores de la independencia del banco central (un indicador basado en cuestionario y otro no) y un indicador de si el país está en vías de desarrollo o es un país desarrollado. Los datos originales y su descripción exhaustiva se encuentran en la URL http://lib.stat.cmu.edu/DASL/Stories/inflation.html . Las variables son:
país
cbi: central bank independence questionnaire index.
inf: tasa de inflación anual (var.respuesta).
legal: central bank independence legal index.
desenv: indicador de si el país es desarrollado (1-Si, 0-No (Ref.))
pais cbi inf legal desenv
23 Ethiopia 1.3 4 4.0 0
22 Yugoslavia 1.7 73 1.7 0
21 Peru 2.2 108 4.3 0
20 Tanzania 3.8 27 4.4 0
19 Turkey 4.4 41 4.6 0
17 Uruguay 4.9 45 2.4 0
16 Uganda 5.3 72 3.8 0
15 Barbados 5.4 7 3.8 0
13 Lebanon 5.9 NA 4.0 0
12 Zaire 6.1 45 4.3 0
7 Bahamas 7.1 6 4.1 0
2 CostaRica 8.1 23 4.7 0
18 Belgium 4.7 5 1.7 1
14 Ireland 5.7 9 4.4 1
10 UKingdom 6.4 7 2.7 1
11 SAfrica 6.4 14 2.5 1
9 France 6.5 7 2.4 1
8 Luxemberg 6.6 5 3.3 1
5 Italy 7.3 11 2.5 1
6 Denmark 7.3 7 5.0 1
4 Australia 7.6 8 3.6 1
3 Finland 7.8 7 2.8 1
1 Germany 10.0 3 6.9 1
Referència
A. Cukierman, S.B. Webb, and B. Negapi, "Measuring the Independence of Central Banks and Its Effect on Policy Outcomes," World Bank Economic Review, Vol. 6 No. 3 (Sept 1992), 353-398.
El diagrama bivariante de la tasa de inflación vs la variable cbi, donde se usan diferentes símbolos para países desarrollados y en vías de desarrollado se muestra a continuación. Valorar la relación entre la tasa de inflación y la variable cbi.
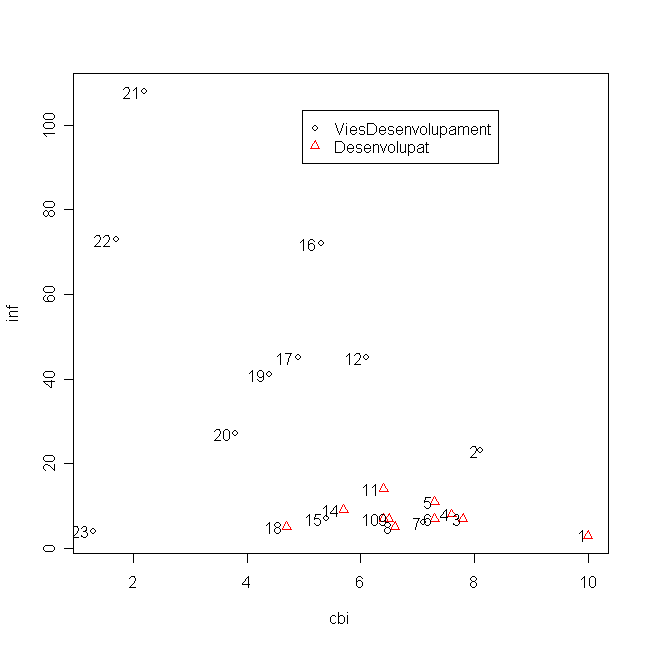
Fijaros en el punto del extremo inferior izquierdo Podríais identificarlo.
A la vista del diagrama bivariante que acompaña la pregunta 1, pensaís que la inflación se relaciona de la misma manera con la variable cbi en paises desarrollados y no desarrollados? Justificar la respuesta. Pensemos en el coeficiente de correlación lineal entre la inflación y el índice cbi para paises en vías de desarrollo: ¿cual es el signo que debería tener y aproximadamente qué magnitud? Pensemos en el coeficiente de correlación lineal entre la inflación y el índice cbi para paises en desarrollados: ¿cual es el valor que le suponeis?
Los resultados del paquete R que seguen a continuación muestran una regresión lineal con variable de respuesta la inflación (inf) y con la variable explicativa dummy que modeliza el grado de desarrollo del país en la reparametrización base-line de los paises no desarrollados. Interpretad los coeficientes. El nivel de desarrollo es estadísticamente significativo? Valorad el contraste por varianza incremental que figura en los resultados.
> options(contrasts=c("contr.treatment","contr.treatment"))
> infla.w2 <- lm(inf ~ fdes, data=infla)
> summary(infla.w2)
Call:
lm(formula = inf ~ fdes, data = infla)
Residuals:
Min 1Q Median 3Q Max
-37.0000 -4.0455 -0.5455 3.8636 67.0000
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 41.000 7.028 5.834 1.05e-05 ***
fdesDesenvolupat -33.455 9.939 -3.366 0.00307 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 23.31 on 20 degrees of freedom
Multiple R-Squared: 0.3616, Adjusted R-squared: 0.3297
> anova(infla.w0,infla.w2,test="F")
Analysis of Variance Table
Modelo 1: inf ~ 1
Modelo 2: inf ~ fdes
Res.Df RSS Df Sum of Sq F Pr(>F)
1 21 17022.4
2 20 10866.7 1 6155.6 11.329 0.003074 **
---
El modelo lineal general con la variable explicativa numèrica cbi y el factor dicotòmico, indicatibo de país desenvolupat o en vies de desarrollo con la reparametrización base-line, se muestra a continuación. Interpretad el modelo y comentad los resultados. Sobreponed las rectas ajustadas al diagrama bivariante del punto 1.
> infla.w3 <- lm(inf ~ fdes + cbi , data=infla)
> summary(infla.w3)
Call:
lm(formula = inf ~ fdes + cbi, data = infla)
…
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 60.437 14.414 4.193 0.000493 ***
fdesDesenvolupat -23.408 11.650 -2.009 0.058936 .
cbi -4.251 2.779 -1.530 0.142576
Residual standard error: 22.57 on 19 degrees of freedom
Multiple R-Squared: 0.4316, Adjusted R-squared: 0.3718
F-statistic: 7.214 on 2 and 19 DF, p-value: 0.004667
Se repite el análisis del punto 5 omitiendo la observación 23. Comentad las diferencias detectadas. Sobreponed las rectas ajustadas al diagrama bivariante del punto 1.
> # Preg. 6 Repetir 5 però sense obs.23
> infla$filtre[ which(infla$pais=="Ethiopia") ] <- FALSE
> infla.w2s <- lm(inf ~ fdes, subset=filtre, data=infla)
> summary(infla.w2s)
Call:
lm(formula = inf ~ fdes, data = infla, subset = filtre)
Residuals:
Min 1Q Median 3Q Max
-38.7000 -3.7000 -0.5455 1.4545 63.3000
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 44.700 7.019 6.368 4.14e-06 ***
fdesDesenvolupat -37.155 9.698 -3.831 0.00113 **
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 22.2 on 19 degrees of freedom
Multiple R-Squared: 0.4358, Adjusted R-squared: 0.4061
F-statistic: 14.68 on 1 and 19 DF, p-value: 0.001127
>
> infla.w3s <- lm(inf ~ fdes + cbi,na.action = na.exclude, subset=filtre, data=infla)
> summary(infla.w3s)
Call:
lm(formula = inf ~ fdes + cbi, data = infla, subset = filtre,
na.action = na.exclude)
Residuals:
Min 1Q Median 3Q Max
-33.883 -7.517 2.231 6.048 42.687
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 82.108 13.684 6.000 1.13e-05 ***
fdesDesenvolupat -21.608 9.601 -2.251 0.03715 *
cbi -7.634 2.523 -3.026 0.00726 **
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 18.57 on 18 degrees of freedom
Multiple R-Squared: 0.6261, Adjusted R-squared: 0.5845
F-statistic: 15.07 on 2 and 18 DF, p-value: 0.0001429
>
> anova(infla.w2s,infla.w3s,test="F")
Analysis of Variance Table
Model 1: inf ~ fdes
Model 2: inf ~ fdes + cbi
Res.Df RSS Df Sum of Sq F Pr(>F)
1 19 9360.8
2 18 6203.9 1 3156.9 9.1596 0.007255 **
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
>
A la vista del contraste formal llistado a continuación, pensaís que el efecto de la variable cbi es diferente en paises desarrollados y en vias de desarrollo con y sin la obs.23 . Comentad comparativamente los resultados y detallad el mejor modelo ANCOVA con y sin la observación 23.
> # Preg. 7 : Interaccions factor - covariable Con /Sin obs 23
> options(contrasts=c("contr.treatment","contr.treatment"))
>
> infla$filtre <- rep(TRUE,length(infla$desenv))
> infla.w4 <- lm(inf ~ fdes * cbi ,subset=filtre, data=infla)
> summary(infla.w4)
Call:
lm(formula = inf ~ fdes * cbi, data = infla, subset = filtre)
Residuals:
Min 1Q Median 3Q Max
-55.4624 -2.7296 -0.1682 5.3042 53.6147
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 66.796 16.573 4.030 0.000785 ***
fdesDesenvolupat -54.986 41.115 -1.337 0.197755
cbi -5.641 3.298 -1.710 0.104394
fdesDesenvolupat:cbi 5.026 6.271 0.802 0.433269
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 22.78 on 18 degrees of freedom
Multiple R-Squared: 0.4512, Adjusted R-squared: 0.3597
F-statistic: 4.933 on 3 and 18 DF, p-value: 0.01131
> infla$filtre[ 23 ] <- FALSE
>
> infla.w4s <- lm(inf ~ fdes * cbi , subset=filtre, data=infla)
> summary(infla.w4s)
Call:
lm(formula = inf ~ fdes * cbi, data = infla, subset = filtre)
Residuals:
Min 1Q Median 3Q Max
-32.1001 -3.9205 -0.3219 3.6781 33.0603
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 99.579 14.804 6.727 3.55e-06 ***
fdesDesenvolupat -87.769 31.577 -2.780 0.01285 *
cbi -11.200 2.818 -3.975 0.00098 ***
fdesDesenvolupat:cbi 10.585 4.855 2.180 0.04358 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 16.89 on 17 degrees of freedom
Multiple R-Squared: 0.7078, Adjusted R-squared: 0.6562
F-statistic: 13.73 on 3 and 17 DF, p-value: 8.474e-05
> # Falten els contrastos
>
> anova(infla.w3,infla.w4,test="F")
Analysis of Variance Table
Modelo 1: inf ~ fdes + cbi
Modelo 2: inf ~ fdes * cbi
Res.Df RSS Df Sum of Sq F Pr(>F)
1 19 9675.2
2 18 9341.8 1 333.4 0.6425 0.4333
> anova(infla.w3s,infla.w4s,test="F")
Analysis of Variance Table
Modelo 1: inf ~ fdes + cbi
Modelo 2: inf ~ fdes * cbi
Res.Df RSS Df Sum of Sq F Pr(>F)
1 18 6203.9
2 17 4848.2 1 1355.7 4.7536 0.04358 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
>
En los siguientes apardos se ha aplicado la transformación logarítmica de la variable de respuesta: le llamaremos log.inf y serà usada como variable de respuesta en los siguientes apartados.
Comentad el diagrama bivariante del logaritmo de la tasa de inflación vs la variable cbi, usando diferentes símbolos para paises desarrollados y en vias de desarrollo. Fijaros en el punto del extremo inferior izquierdo.
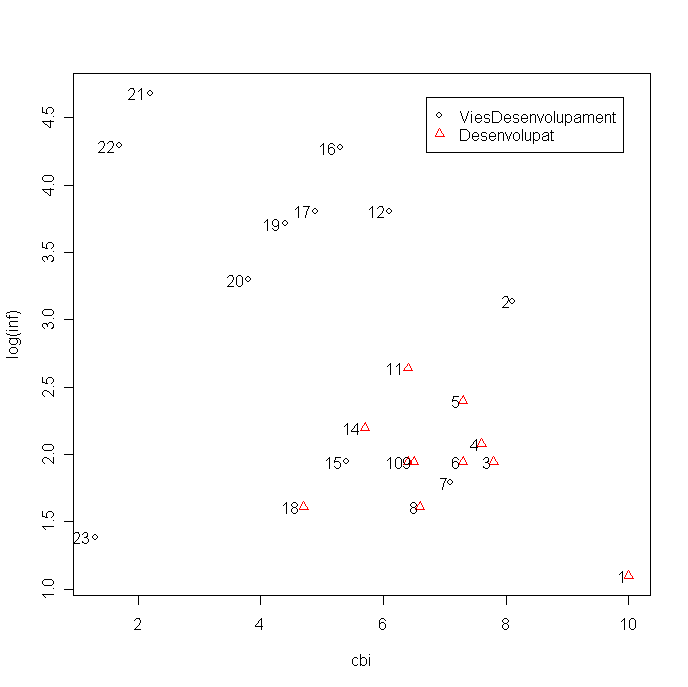
Los resultados muestran un modelo lineal con la variable explicativa cbi y la variable dummy que modeliza el grado de desarrollo del país en base-line de paises no desarrollados. Interpretad el modelo para los 2 tipos de país y justificad si la relación entre el logaritmo de la inflación y el cbi es el mismo para paises desarrollados y no desarrollados.
> infla$filtre[ which(infla$pais=="Lebanon") ] <- FALSE
>
> infla.lw0 <- lm(log(inf) ~ 1 , subset=filtre, data=infla)
> infla.lw0
Call:
lm(formula = log(inf) ~ 1, data = infla, subset = filtre)
Coefficients:
(Intercept)
2.616
>
> options(contrasts=c("contr.treatment","contr.treatment"))
> infla.lw2 <- lm(log(inf) ~ fdes , subset=filtre, data=infla)
> summary(infla.lw2)
Call:
lm(formula = log(inf) ~ fdes, data = infla, subset = filtre)
Residuals:
Min 1Q Median 3Q Max
-1.898383 -0.290314 0.005137 0.504264 1.397454
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 3.2847 0.2526 13.005 3.24e-11 ***
fdesDesenvolupat -1.3379 0.3572 -3.746 0.00127 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.8377 on 20 degrees of freedom
Multiple R-Squared: 0.4123, Adjusted R-squared: 0.3829
F-statistic: 14.03 on 1 and 20 DF, p-value: 0.001275
>
> summary(infla.lw3)
Call:
lm(formula = log(inf) ~ fdes + cbi, data = infla, subset = filtre)
Residuals:
Min 1Q Median 3Q Max
-2.1938 -0.2904 0.1080 0.5346 1.1833
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 3.69737 0.53836 6.868 1.49e-06 ***
fdesDesenvolupat -1.12456 0.43514 -2.584 0.0182 *
cbi -0.09025 0.10379 -0.870 0.3954
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.8429 on 19 degrees of freedom
Multiple R-Squared: 0.4348, Adjusted R-squared: 0.3753
F-statistic: 7.307 on 2 and 19 DF, p-value: 0.004428
>
> anova(infla.lw2,infla.lw3,test="F")
Analysis of Variance Table
Modelo 1: log(inf) ~ fdes
Modelo 2: log(inf) ~ fdes + cbi
Res.Df RSS Df Sum of Sq F Pr(>F)
1 20 14.0348
2 19 13.4976 1 0.5372 0.7561 0.3954
Se han calculado los factores de anclaje de uno de los modelos que aparecen en el apartado 9. ¿Cuál es el umbral màximo a partir del cual una observación se denomina influente a priori con el juego de datos completo actual ? Comentad brevemente los 4 paises con factor d’anclaje elevado. ¿Por qué pensaís que Costa Roca encabeza la lista?
> # Con obs 23.
> par(mfrow=c(1,1))
> hatvalues(infla.lw3)
23 22 21 20 19 17 16
0.25332284 0.21604788 0.17627782 0.09996341 0.09136149 0.09253323 0.09892952
15 12 7 2 18 14 10
0.10128678 0.12627920 0.18776082 0.27956970 0.16674729 0.11408814 0.09527145
11 9 8 5 6 4 3
0.09527145 0.09379645 0.09262471 0.09291420 0.09291420 0.09758735 0.10221915
1
0.23323291
>
Se han calculado los residuos estudentizados de uno de los modelos que aparecen en el apartado 9 y se ha dibujado el diagrama bivariante con ordenadas los residuos y en abscisas los factores de anclaje. Comentd los resultados. ¿Pensaís que alguno de los paises es un outlier?
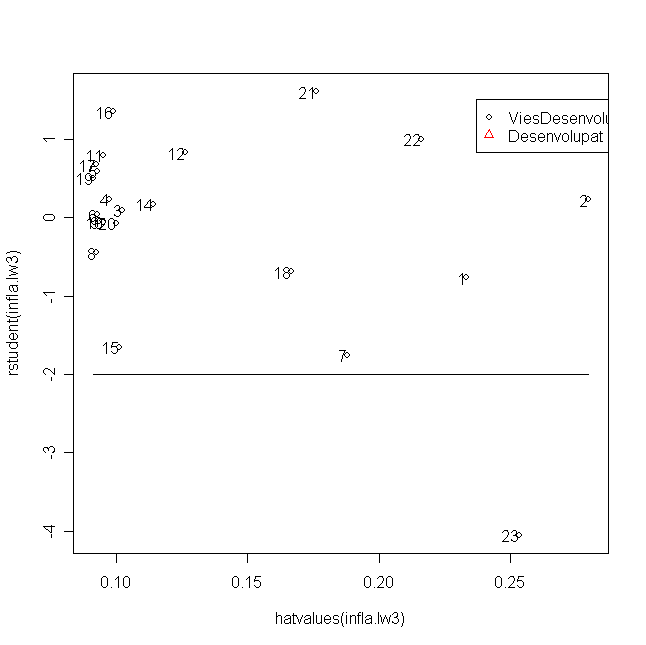
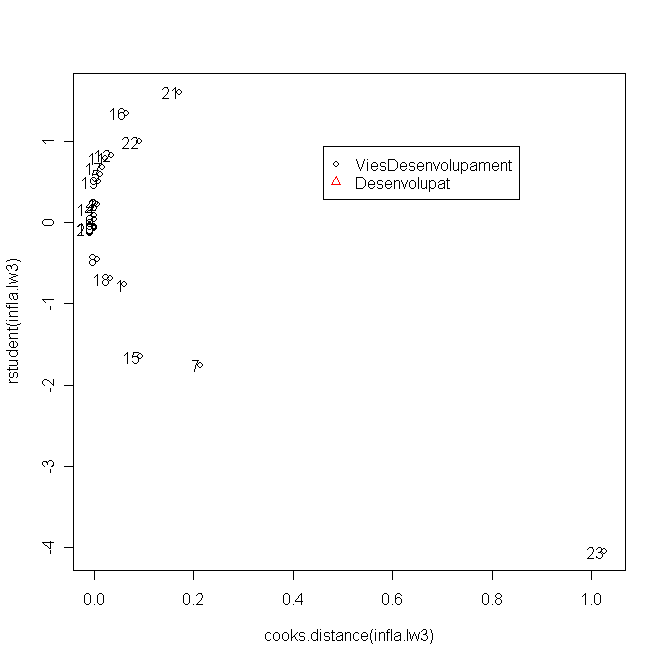
Calculad el umbral de Chatterjee-Hadi para las distancias de Cook de las observaciones del modelo lw3. Indicad a la vista de la lista de paises que superan este umbral, si hay alguna observación influyente a posteriori. ¿Por qué pensaís que Etiopia es más influyente que Alemania?
> infla$filtre <- rep(TRUE,length(infla$desenv))
> infla$filtre[ which(infla$pais=="Lebanon") ] <- FALSE
> cooks.distance(infla.lw3)
23 22 21 20 19 17
1.026026e+00 9.192219e-02 1.706901e-01 1.987009e-04 8.869490e-03 1.603751e-02
16 15 12 7 2 18
6.395104e-02 9.402657e-02 3.379231e-02 2.136355e-01 7.232298e-03 3.276188e-02
14 10 11 9 8 5
1.314909e-03 1.326995e-04 2.263997e-02 8.690069e-05 7.137556e-03 1.240809e-02
6 4 3 1
5.403322e-05 2.084505e-03 3.533630e-04 6.083442e-02
>
Ahora cambiando de anàlisis se quiere determinar si es posible clasificar los paises desarrollados y no desarrollados en función de la su tasa de inflación anual (infl) y del index cbi, la variable de respuesta dicotòmica serà si el país es o no desarollado (desenv). Se ensayan modelos de respuesta binaria con enlacee logit. Calculad manualmente el modelo nulo. ¿ Cual es el estimador de la constante?
Cuál es el AIC del modelo?
> options(contrasts=c("contr.treatment","contr.treatment"))
> fla.w0 <- glm(desenv ~ 1, family=binomial, data=fla)
> summary(fla.w0)
Call:
glm(formula = desenv ~ 1, family = binomial, data = fla)
Deviance Residuals:
Min 1Q Median 3Q Max
-1.141 -1.141 -1.141 1.215 1.215
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -0.08701 0.41742 -0.208 0.835
(Dispersion parameter for binomial family taken to be 1)
> logLik(fla.w0)
'log Lik.' -15.92064
A la vista de los resultados de los siguientes modelos, seleccionad el mejor modelo justificando estadísticamente la respuesta.
Interpretad la/s variable/s explicativa/s del mejor modelo en la escala logit.
Interpretad la/s variable/s explicativa/s del mejor modelo en la escala de los odds.
Interpretad la/s variable/s explicativa/s del mejor modelo en la escala de las probabilidades.
Calculad el coeficiente de determinación generalizado del mejor modelo.
Determinad cual es la probabilidad de ser un país desarrollado aquel que muestra un valor de cbi de 6 y una tasa anual de inflación del 10%, según el mejor modelo.
> fla.w1 <- glm(desenv ~ cbi, family=binomial, data=fla)
> summary(fla.w1)
Call:
glm(formula = desenv ~ cbi, family = binomial, data = fla)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -5.3550 2.6117 -2.050 0.0403 *
cbi 0.8843 0.4182 2.115 0.0344 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 31.841 on 22 degrees of freedom
Residual deviance: 23.160 on 21 degrees of freedom
AIC: 27.160
Number of Fisher Scoring iterations: 5
> fla.w2 <- glm(desenv ~ inf, family=binomial, data=fla)
> summary(fla.w2)
Call:
glm(formula = desenv ~ inf, family = binomial, data = fla)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 2.27892 1.03169 2.209 0.0272 *
inf -0.15361 0.08523 -1.802 0.0715 .
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 30.498 on 21 degrees of freedom
Residual deviance: 17.272 on 20 degrees of freedom
(1 observation deleted due to missingness)
AIC: 21.272
Number of Fisher Scoring iterations: 7
> fla.w3 <- glm(desenv ~ cbi + inf,family=binomial, data=fla)
> summary(fla.w3)
Call:
glm(formula = desenv ~ cbi + inf, family = binomial, data = fla)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -1.8164 2.7219 -0.667 0.505
cbi 0.7698 0.5010 1.536 0.124
inf -0.2217 0.1442 -1.537 0.124
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 30.498 on 21 degrees of freedom
Residual deviance: 13.368 on 19 degrees of freedom
(1 observation deleted due to missingness)
AIC: 19.368
Number of Fisher Scoring iterations: 8
>
Tags: transport, (upc), màster, logística, mobilitat
- COMISIÓN TÉCNICA NACIONAL DE AEROMODELISMO REGLAMENTACIÓN DE LA
- VICTIMS OF CRIME ACT (VOCA) VICTIM ASSISTANCE GRANT PROGRAM
- DOTVÁRANIE PRÁVA SÚDNYM VÝKLADOM CIEĽOM JE PREZENTOVAŤ PRÁVNE VÝCHODISKÁ
- CRNRDC41 PÁGINA 2 OMPI CRNRDC41 ORIGINAL INGLÉS FECHA 11
- SOIL ORGANIC MATTER NAME DAYPERIOD INTRODUCTION WHAT IS SOIL
- REFERENCE TO SUPPORT PREAPPLICATION FOR UKPHR’S SPECIALIST REGISTRATION BY
- MEMORIAL TREES MEMORIAL TREES ARE PLANTED WITHIN A DESIGNATED
- FACSIMILE DOMANDA DI ISCRIZIONE ALL’ORDINE CONSULENTI DEL LAVORO
- DECRETO 161 DE 1999 (ENERO 21) ALCALDIA MAYOR DE
- APPENDIX I UKRAINE ANNEX 1 PAGE 14 UKRAINE (AUTHENTIC
- LOS PRONOMBRES DE COMPLEMENTO DIRECTO E INDIRECTO A TRAVÉS
- KEY CHEMISTRY MOLARITY OF SOLUTIONS DIRECTIONS SOLVE EACH
- DERECHO DE SUCESIONES EL ORDEN DE SUCEDER EN LA
- EUROS POR TONELADA211 ANEXO I SOLICITUD DE CERTIFICADO PARA
- GRADUACIÓN DE CRITERIOS DE EVALUACIÓN DEL ÁREA DE EDUCACIÓN
- RMDS ESB NETWORKS IRISH RETAIL ELECTRICITY MARKET MARKET DESIGN
- SCHEDA SINTETICA ART 15 COMMA 1 DLGS N 332013
- SWEET AND SALT FMSN DISCOVERY STATION SOLUTIONS MOLARITY IS
- Development of a Smart Devicebased Telemetry and Photograping System
- SAEZ GONZÁLEZ JULIA DEL CARMEN C ASTRADA ARMANDO VALENTÍN
- YAHYA RIBHE TAHBOUB DEPARTMENT OF APPLIED CHEMISTRY FACULTY OF
- E JERCICIO 1 MICROSOFT WORD INFORMÁTICA 1° CB CONSTRUCCIONES
- DECREE OF GENERAL ADMINISTRATION OF CUSTOMS OF THE PEOPLE’S
- ACTELE NECESARE ÎNTOCMIRII DOSARULUI ÎN VEDEREA BENEFICIERII DE DREPTURILE
- OBRAZAC 1 – PRIJAVA FIZIČKE OSOBE VOLONTERAVOLONTERKE ZA NAGRADU
- DIRECTIONS TO M & T BANK STADIUM 1101 RUSSELL
- DANIEL ALDAYA MARÍN (PAMPLONA 1976) AUTOR DE LOS POEMARIOS
- ANMELDELSE AF ASBESTHOLDIGT AFFALD KOMMUNENS NAVN OG ADRESSE HØJETAASTRUP
- GRADO EN FARMACIA PRÁCTICAS EXTERNAS FACULTAD DE FARMACIA SOLICITUD
- AYUDAS PARA CONTRATOS PREDOCTORALES DE LA USAL COFINANCIADAS POR
PRIJAVNI OBRAZAC ZA DODJELU STIPENDIJA STUDENTIMA OPĆINE TOMISLAVGRAD ZA
 FICHA OFICIALIZACIÓN GRUPOS DE INVESTIGACIÓN INSTITUCIONAL CENTRO DE INVESTIGACIÓN
FICHA OFICIALIZACIÓN GRUPOS DE INVESTIGACIÓN INSTITUCIONAL CENTRO DE INVESTIGACIÓN ADATLAP TÁMOGATÁSI IGÉNYLÉSHEZ 1 A TÁMOGATÁSI IGÉNNYEL ÉRINTETT TEVÉKENYSÉG
ADATLAP TÁMOGATÁSI IGÉNYLÉSHEZ 1 A TÁMOGATÁSI IGÉNNYEL ÉRINTETT TEVÉKENYSÉGPROGRAM RADIONICE »FIZIOTERAPIJSKA PRENATALNA EDUKACIJA TRUDNICA» 5 ŠKOLSKIH SATI)
 WITAM WAS SERDECZNIE DZISIAJ BĘDZIECIE DODAWAĆ LICZBY DWUCYFROWE ZACZNIEMY
WITAM WAS SERDECZNIE DZISIAJ BĘDZIECIE DODAWAĆ LICZBY DWUCYFROWE ZACZNIEMY SHARP INFORMACIÓN CORPORATIVA HISTORIA SHARP CORPORATION FUE FUNDADA EN
SHARP INFORMACIÓN CORPORATIVA HISTORIA SHARP CORPORATION FUE FUNDADA EN D EPARTAMENT D’ANÀLISI MATEMÀTICA ANUNCIO DE CONFERENCIA SEMINARIO DE
D EPARTAMENT D’ANÀLISI MATEMÀTICA ANUNCIO DE CONFERENCIA SEMINARIO DE ISTITUTO COMPRENSIVO STATALE “LE CURE” VIA GOITO 20
ISTITUTO COMPRENSIVO STATALE “LE CURE” VIA GOITO 20 ANEXA NR 7 LA REGULAMENTUL COMISIEI MEDICAMENTELOR VETERINARE ACT
30 JANUAR 2012 REFERAT AF SKOLERÅDETS MØDE DEN 26
STATUT SOŁECTWA MACIEJOWA ROZDZIAŁ I NAZWA I TEREN DZIAŁANIA
LISTA PODRĘCZNIKÓW DLA KLAS II (PO SZKOLE PODSTAWOWEJ) W
ISTRAŽIVAČKI NACRT NAZIV I TEMA ISTRAŽIVANJA ISPITIVANJE POTREBA DECE
 2 LIETUVOS RESPUBLIKOS SVEIKATOS APSAUGOS MINISTRAS ĮSAKYMAS DĖL SKUBIOSIOS
2 LIETUVOS RESPUBLIKOS SVEIKATOS APSAUGOS MINISTRAS ĮSAKYMAS DĖL SKUBIOSIOSZAŁĄCZNIK NR 1 DNIA 2020 R ……………………………… NAZWA
O‘ZBEKISTON RESPUBLIKASI OLIY VA O‘RTA MAXSUS TA’LIM VAZIRLIGI ANDIJON
 SECCION DE ESCUELASTALLER PINTOR LORENZO CASANOVA 6
SECCION DE ESCUELASTALLER PINTOR LORENZO CASANOVA 6  GUIDE TO APPLYING FOR A PROMOTER LICENCE THIS GUIDE
GUIDE TO APPLYING FOR A PROMOTER LICENCE THIS GUIDE 42 HIERARCHICAL COMPLEXITY AND TASK DIFFICULTY MICHAEL LAMPORT COMMONS
42 HIERARCHICAL COMPLEXITY AND TASK DIFFICULTY MICHAEL LAMPORT COMMONSITH149COM13G – PAGE 3 CONVENTION FOR THE SAFEGUARDING OF
