UNIVERSITÉ D’OTTAWA · UNIVERSITY OF OTTAWA ÉCOLE DINGÉNIERIE ET
Contacts Extérieurs 20022003 N Dess Clabd 20022003 Université deUniversité Paris Diderot Paris 7 Faculté DE Médecine
University of Ottawa

Université d’Ottawa · University of Ottawa
École d'ingénierie et de technologie School of Information Technology
de l'information (EITI) and Engineering (SITE)
CEG 4131 Computer Architecture III: MIDTERM
|
Date: October 28th |
Professor: Dr. M. Bolic |
|
Duration: 75minutes |
Session: Fall 2005-2006 |
|
Total Points = 100 plus 7 bonus points |
|
Note: Closed book exam. Cheat-sheets are not allowed. Calculators are allowed.
Name: _______________________Student ID:_______________
QUESTION #1 (each question is 5 points, total 20)
Define, compare and comment on the following (within 1-3 sentences each):
Two processors require access to the same line of data from data memory. Processors have a cache and use the write-back write invalidated (MSI) protocol. Is it possible for two processors that share the same bus to repeatedly invalidate each other’s data even though they do not share any variable?
It is possible if processors write to the different addresses in the main memory which belong to the same cache line.
Does efficiency of a program running on a parallel machine depend on the problem size (in the parallel addition problem, the problem size is the number of elements to add in parallel)? Why?
Yes, since speed-up depend on the problem size. Better speed-up can be achieved if we increase the problem size because less relative time will be used for overhead.
What is the difference between the lock and the barrier?
Barrier is used for global synchronization. Barriers ensure that n processes will come to the same point defined by barrier. Locks are used for mutual exclusion when the shared variable is accessed.
Explain the difference among the full-map, limited and chained directories in the directory protocols.
Full-map and limited directory are centralized directories while chained is a distributed directory. Difference between full-mapped and limited is that in full-mapped there are one bit per each cache. In order to decrease the size of directories, the directories with fixed number of pointers are used (limited directories).
QUESTION #2 (a 15 points, b 15 points, total 30 points)
Consider a multiprocessor system with 3 processors P1, P2 and P3. Assume that they are connected either using a shared bus, linear array or a ring. At time instant 1, all three processors would like to send a message: P1 should send to P2, P2 to P3, and P3 to P1. Assume every link of every interconnect is the same speed. How long does this communication take and why?
Bus
3 time units – data has to be sent sequentially
Ring
1 time unit – data can be sent simultaneously through each link
Linear array
3 time units – data is sent at the same time from P1->P2 and P2->P3. After this, 2 time units are needed to send a message from P3 to P2.
Answer the following questions:
What is the diameter of a star network with 16 processors?
2
What is the bisection width of a linear array with 32 processors?
1
What is the number of 2x2 switches in a 16x16 baseline multistage network?
32
QUESTION #3 (a 19 points, b 15 points (b1 to b3 each 5 points), total 34 points)
A four-processor shared-memory system implements the MESI protocol for the cache coherence. For the following sequence of memory references, show the state of the line containing the variable a in each processor’s cache after each reference is resolved. Each processors start out with the line containing a invalid in their cache.
|
|
State of P0’s cache |
State of P1’s cache |
State of P2’s cache |
State of P3’s cache |
|
|
P0 reads a |
E |
I |
I |
I |
(3pt) |
|
P1 reads a |
S |
S |
I |
I |
(3pt) |
|
P2 reads a |
S |
S |
S |
I |
(3pt) |
|
P3 writes a |
I |
I |
I |
M |
(5pt) |
|
P0 reads a |
S |
I |
I |
S |
(5pt) |
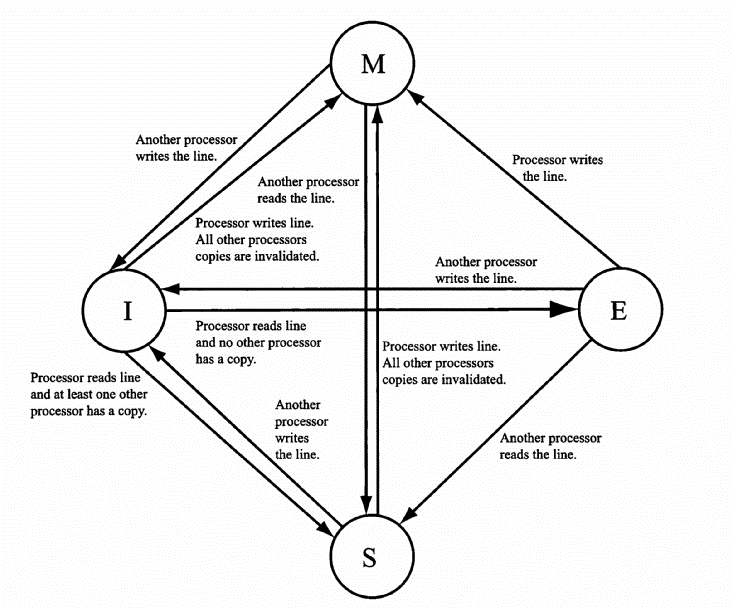
MESI cache coherence protocol
Consider a multiprocessing system with 8 processors that have their local caches and they are connected to the main memory.
If Full Map Directory cache coherence protocol is implemented, what is the number of bits per directory? Why?
1 bit is used per processor, so that the number of bits is 8
If Limited Directory cache coherence protocol with only two pointers is implemented, what is the number of bits per directory? Why?
Log28=3, the number of bits per pointer is 3 and the total number of bits is 6
Assume that Full Map Directory cache coherence protocol with Centralized Directory Invalidate is implemented. Assume that directory for address X contained all 0s at the beginning. Fill the following table for the following sequence of instructions:
|
Time instant |
Operation |
Content of the directory for X |
|
1 |
Processor 0 – read X |
00000001 |
|
2 |
Processor 5 – read X |
00100001 |
|
3 |
Processor 0 – writes to X |
00000001 |
(From Lecture Notes) Centralized Directory Invalidate
Invalidating signals and a pointer to the requesting processor are forwarded to all processors that have a copy of the block. Each invalidated cache sends an acknowledgment to the requesting processor. After the invalidation is complete, only the writing processor will have a cache with a copy of the block.
QUESTION #4 (a 10 points, b 6 points, c 7 points, total 23 points)
Consider a machine with 2 processors that share the same memory. Multiply and Accumulate operation is performed:
global_MAC= X[0]*Y[0]+ X[1]*Y[1]+… X[N-1]*Y[N-1]
The MAC subroutine is implemented on both processors and it is shown bellow.
Modify the program to make it suitable for execution in a four-processor machine.
Lines 9 and 16: BARRIER (4)
Line 11: for (i =id*N/4; i < (id+1)*N/4; i++)
If processor P1 starts executing MAC subroutine before the processor P0, will the final result be different. Why?
No, the result will be the same because the processors are synchronized using BARRIER.
Suppose that we implement a similar program using NIOS IIf processors which have write-back caches and do not support cache coherence protocols. Will there be cache coherence problems? If yes, with which variable? Why?
Yes there will be cache coherence problems with global_MAC. After updating global_MAC by one processor, the old value of the global_MAC will still be in the main memory because of write-back cache coherence policy. Since, there is no cache coherence protocols implemented, the other processor will get non-updated value of global_MAC.
1. id = mypid (); // Assign identification number: id=0 for processor 0, and id=1 for processor 1
2. read_array(X, Y, N); //read arrays X and Y that have size N
3. if (id == 0) //initialize the MAC
4. {
5. LOCK(global_MAC);
6. global_MAC = 0;
7. UNLOCK(global_MAC);
8. }
9. BARRIER(2); //waits for all processors to get to this point in the program
10. local_MAC = 0;
11. for (i =id*N/2; i < (id+1)*N/2; i++)
12. local_MAC += X[i]*Y[i];
13. LOCK(global_MAC);
14. global_MAC += local_MAC;
15. UNLOCK(global_MAC);
16. BARRIER(2); //waits for all processors to get to this point in the program
17. END;
Tags: dingénierie, d’ottawa, école, ottawa, université, university
- CHS DAILY BULLETIN WEEK OF MAY 17 THRU 21
- BUDAPEST UNIVERSITY OF TECHNOLOGY AND ECONOMICS FACULTY OF CHEMICAL
- DALL’ILIADE RIASSUNTO DEL BRANO “LA MORTE DI ETTORE” ETTORE
- HEAD COACH CEP LEVEL YEAR EXPIRED SIGNATURE ASST
- INTRODUCCIÓN | 15 INTRODUCCIÓN EN ESTA COMPILACIÓN SE
- MÚSICA LA MÚSICA COMO BIEN CULTURAL Y COMO LENGUAJE
- ANEXO 3 CONSENTIMIENTO INFORMADO AMPLIO PARA USO DE DATOS
- KRAJEVNA SKUPNOST DOKLEŽOVJE GLAVNA ULICA 18 9231 BELTINCI
- 7 HỘI ĐỒNG NHÂN DÂN TỈNH NAM ĐỊNH SỐ
- INTRODUÇÃO AO PROCESSO DE POISSON A DISTRIBUIÇÃO DE
- FIRST AND SECOND GRADE SCREENING SPEECH AND LANGUAGE NAME
- Rotation Rotation Rotation Cover Crops can Suppress Weeds Weeds
- CÔNG TY CP PHẦN MỀM MELIASOFT MELIASOFT JOINT STOCK
- TEXTOS PRIMER CICLO PRIMARIA (PRIMERO) NIVEL EDITORIAL TÍTULO 1º
- BİNALARDA TOPRAKLAMA TESİSLERİNDE YAPILACAK GÖZLE MUAYENEDENETLEME VE ÖLÇMEYE İLİŞKİN
- 0 N248802 JANUARY 16 2014 CLA284OTRRNC1104 CATEGORY CLASSIFICATION TARIFF
- 3 OMAR OBANDO SUÁREZ 5 DE OCTUBRE 2004 DIVISIÓN
- JADWAL KEGIATAN PESERTA MAGANG DIKTI DI PUSAT PENGEMBANGAN PENDIDIKAN
- FICHE PROFESSEUR THÈME DU PROGRAMME 1ÈRES OBSERVER –
- ANNUAL AUDITED ACCOUNTS CHECKLIST AGENCY AAAS REPORTING YEAR DATE
- UNIVERSIDAD CENTRAL DE VENEZUELA FACULTAD DE FARMACIA CONSEJO DE
- INTRODUCCIÓN EL REINO UNIDO DE GRAN BRETAÑA E IRLANDA
- DODATAK 5 KRITERIJI ODABIRA PROJEKTNIH PRIJEDLOGA ZA PROVEDBU LRS
- INFORMATION TILL DIG I ÅK 6 OCH 7 INFÖR
- LIQUIDATED SAVINGS FOR EARLY COMPLETION (REV 51899) (FA
- CHAPTER 7 FAILUREPRONE PRODUCTION LINES ??? DUE IN ???
- INTRODUCCIÓN AL ANÁLISIS DE DATOS TEMA 5 INTRODUCCIÓN
- GROUP 1 NEURAL NETWORKS IN POWDER METALLURGY DRAGOLJUB DRNDAREVIC
- ACTE NORMATIVE DIN DOMENIUL MUNCII HOTARÎREA GUVERNULUI NR26
- 2 E VALUACIÓN MANEJO DE MATERIALES Y DESPERDICIOS DE
 AVISO RENDIMIENTO ESTUDIANTIL Y RECOMENDACIÓN DE PARTICIPACIÓN EN LA
AVISO RENDIMIENTO ESTUDIANTIL Y RECOMENDACIÓN DE PARTICIPACIÓN EN LAIDE MIDDLEWARE AND HARDWARE BUNDLE FOR EMBEDDED DEVELOPMENT SEGGERS
252 GROUPS JULY 2016 WEEK 4 SMALL GROUP K1
BATI AKDENİZ İHRACATÇILAR BİRLİĞİ ÜYELERİNE SİRKÜLER 2020348 SAYIN ÜYEMIZ
CDSSF432001 NCNB005 NORMAS PARA EL RECONOCIMIENTO CONTABLE DE PÉRDIDAS
 CUADERNILLO PRIMARIA 3ª OEMEPS 2012 SECRETARÍA DE EDUCACIÓN JALISCO
CUADERNILLO PRIMARIA 3ª OEMEPS 2012 SECRETARÍA DE EDUCACIÓN JALISCO MODELLO 11BIS DATA DI ARRIVO ALLO SPORTELLO UNICO PER
MODELLO 11BIS DATA DI ARRIVO ALLO SPORTELLO UNICO PERDRAWING THE LINE BETWEEN MEANING AND IMPLICATURE AND RELATING
 WIKINGOWIE ŁUPIEŻCY I EKSPLORATORZY POWIADALI ZDYCHA CI BYDŁO UMIERAJĄ
WIKINGOWIE ŁUPIEŻCY I EKSPLORATORZY POWIADALI ZDYCHA CI BYDŁO UMIERAJĄ DIRECTIONS TO FRAMINGHAM OFFICE 665 COCHITUATE ROAD FRAMINGHAM
DIRECTIONS TO FRAMINGHAM OFFICE 665 COCHITUATE ROAD FRAMINGHAMSUTTON ELEMENTARY SCHOOL TITLE I PART A PARENTAL INVOLVEMENT
ZAŁĄCZNIK NR 3 UMOWY REGULAMIN CZYSZCZENIA POJAZDÓW KOLEJOWYCH I
 H EZKUNTZA IRAUNKORRAREN EREMUAN KOKATUTAKO MINTEGIAK DIRA BIZITZA OSOAN
H EZKUNTZA IRAUNKORRAREN EREMUAN KOKATUTAKO MINTEGIAK DIRA BIZITZA OSOANTELEVERKSAMHET 2008 TK0901 A ALLMÄNNA UPPGIFTER A1 ÄMNESOMRÅDE TRANSPORTER
6 METALŲ LAUŽO PIRKIMO PARDAVIMO SUTARTIS [NURODYTI SUTARTIES
 ZŠ KLATOVY PLÁNICKÁ UL 194 WWWZSKLATOVYPLANICKACZ TEL 376 313
ZŠ KLATOVY PLÁNICKÁ UL 194 WWWZSKLATOVYPLANICKACZ TEL 376 313 RESIDENTIAL PRIORITY PARKING PERMIT AND VISITOR VOUCHERS APPLICATION CITY
RESIDENTIAL PRIORITY PARKING PERMIT AND VISITOR VOUCHERS APPLICATION CITYPRUEBAS ACCESO A CICLOS DE GRADO MEDIO Y GRADO
CARTÓRIOS EM SÃO LUÍS MUNICÍPIO SÃO LUÍS SERVENTIA 1ª
A NET FULL OF FISHES JOHN 21125 LESSON 114
