A DISTRIBUTED MULTIMEDIA DATA MANAGEMENT OVER THE GRID KASTURI
89590 DISTRIBUTED SYSTEMS WHY DISTRIBUTED SYSTEMS?!doctype Html html Langenus head meta Charsetutf8script Typetextjavascript(windownreum||(nreum{}))init{privacy{cookiesenabledtrue}ajax{denylist[bamnrdatanet]}distributedtracing{enabledtrue}}(windownreum||(nreum{}))loaderconfig{}! for
1 CS451 INTRODUCTION TO PARALLEL AND DISTRIBUTED COMPUTING
1 FM 92XII GRIB GENERAL REGULARLYDISTRIBUTED INFORMATION IN
13 DISTRIBUTED BY VERITAS VERITAS MAKES EVERY EFFORT TO
15 DISTRIBUTED BY VERITAS VERITAS MAKES EVERY EFFORT TO
Distributed computing uses the computing power of multiple computers or clusters of computers to provide the user with a virtual supercomputer
A Distributed Multimedia Data Management over the Grid
Kasturi Chatterjee
Distributed computing uses the computing power of multiple computers or clusters of computers to provide the user with a virtual supercomputer. Grid computing is a form of distributed computing which combines the power of several computers of varied computing resources to execute one or more task collaboratively in a seamless and transparent manner. In 2000, Ian Foster along with Steve Tuecke, defined that Grid computing is concerned with “coordinated resource sharing and problem solving in dynamic, multi-institutional virtual organizations” [1]. Many applications leverage the huge computing power of Grid to make things faster and efficient. Multimedia applications are one of the most popular and most used applications in today’s world. With the proliferation of internet and information technology, the availability of numerous sources of video, images, text and other multimedia data has become easy. They are used for varied purposes like education, entertainment, business etc. The sheer size of multimedia data like a video makes distributing it over a shared and distributed environment and utilizing the computing power of grids a likely choice. A distributed environment storing multimedia data will enable a user to share and use the multimedia data from a distant node without wasting storage space in his/her own local machine by making a duplicate copy. Thus, a connected group of users forming a grid can utilize the collective computing power and storage of multiple computers to solve different issues. But the atypical nature of multimedia data makes its management, especially in a distributed environment, a daunting task. The two most important characteristics of multimedia data that makes it different from traditional data are (1) high dimensionality and (2) semantic interpretation. Multimedia data is represented as multidimensional feature vectors and semantic meanings are tagged to them by the users based on perception. These two characteristics of multimedia data provides the impetus for developing special techniques to better manage them. Here, we propose an efficient multimedia data management over a distributed environment like grid.
Management of multimedia data involves three important parts: Firstly, the extraction of content /features from the videos/images. This is a very important step since to identify the feature sets that best describes a multimedia content determines the effectiveness and success of the subsequent processing. Secondly, storing and indexing of multimedia data. The huge volume of multimedia data requires an efficient storage and indexing which takes care of the special nuances of multimedia data viz. the high dimensionality and the gap between low-level features and high-level semantic interpretation. Finally, efficient retrieval of multimedia data. The most popular among the different retrieval approaches is content-based image/video retrieval. In this project, we propose to primarily achieve the second part, which is the backbone of efficient multimedia data management, over a grid. However, to achieve it efficiently, effective execution of the first and third parts is equally crucial. We will implement a multidimensional index structure, the affinity hybrid tree [2], in a distributed environment and devise content-based retrieval algorithms supported by the index structure over a grid. The index structure and the subsequent retrieval methodologies coupled with it, is independent of the features used to represent the multimedia data and the techniques adopted to interpret users’ preference during content-based retrieval. The index structure demonstrates encouraging results in single node architecture both in terms of low computational overhead and relevance of query results (which measures how close the retrieval results are to the users’ perception). In the single node architecture, we used a matrix, called affinity relationship [3], which captures the high-level image/video relationship using a probabilistic model called hidden markov model mediator. Here we plan to use a different representation of the affinity relationship in the form of a hierarchical distributed and often replicated structure, to capture and use the high-level semantic relationships and utilize them while content-based retrieval effectively.
Reference:
[1] Ian Foster, “What is the Grid? A Three Point Checklist”,2002.
[2] Kasturi Chatterjee and Shu-Ching Chen, "A Novel Indexing and Access Mechanism using Affinity Hybrid Tree for Content-Based Image Retrieval in Multimedia Databases," International Journal of Semantic Computing (IJSC), Vol. 1, Issue 2, pp. 147-170, June 2007.
[3] Mei-Ling Shyu, Shu-Ching Chen, Min Chen, Chengcui Zhang, and Chi-Min Shu, "MMM: A Stochastic Mechanism for Image Database Queries," Proceedings of the IEEE Fifth International Symposium on Multimedia Software Engineering (MSE2003), pp. 188-195, December 10-12, 2003, Taichung, Taiwan, ROC.
30 GUIDE TO NOTES OVERVIEW MULTISTEP AND DISTRIBUTED PROCESSING
39 DISTRIBUTED BY VERITAS VERITAS MAKES EVERY EFFORT TO
6 DISTRIBUTED BY VERITAS TRUST TEL [263] [4] 794478
Tags: distributed multimedia, hierarchical distributed, multimedia, management, distributed, kasturi
- GENERAL COMMENTS I DID NOT FIND IT EASY
- CARMEN – COOPERATIVE FOR THE ADVANCEMENT OF RESEARCH THROUGH
- BÀN VỀ TIÊU CHUẨN NGHIỆM THU CHẤT LƯỢNG THI
- KLASA 36302130104 URBROJ 213710138 OD 10 SVIBNJA 2013 NA
- T AX ACTION TAX ACTIVITY AND CREATIVITY COMPETITION TAX
- CATÁLOGO DE CURSOS 20042005 SELECCIONE LOS CURSOS DE SU
- 28 DE DICIEMBRE DE 1878 LEY ELECTORAL DON ALFONSO
- RATE RDSRIDER PPO CONTRACT DELIVERY SERVICES AND POWER PURCHASE
- REPÚBLICA DE COLOMBIA RAMA JUDICIAL CONSEJO SUPERIOR DE LA
- FORMULARIO SOLICITUD ESPACIOS COSTEROS MARITIMOS PARA PUEBLOS ORIGINARIOS (ECMPO)
- WWWSCIENCETEACHERSCOMEARTHHTM NAME ACROSS 6 TYPE OF ROCKS
- IMG SRCHTTPPXLCTLELPAISCOMPXLCTLGIF?M1&R2 WIDTH1 HEIGHT1 ALT JUAN JOSÉ MILLÁS
- BO OG LEVEBESKRIVELSE FOR SJØMANNSKIRKEN I ALBIRVILLAJOYOSA 1 SJØMANNSKIRKEN
- R AQUEL SAIZ ACTRIZ NOMBRE Y APELLIDOS RAQUEL SÁIZ
- CHU 1 BRYAN CHU MR AHUMADA ENG 4UP01 4
- ANSØGNING OM GODKENDELSE AF NY ANSVARLIG LEDER (OFFENTLIG SERVICETRAFIK)
- ZAŁĄCZNIK NR 1 DO REGULAMIN REKRUTACJI I UCZESTNICTWA W
- AMENDMENT NO […]1 TO THE […]2 BETWEEN THE UNITED
- YOZGAT BOZOK ÜNİVERSİTESİ GÜVENLİ KAMPÜS ÖZ DENETİM PROSEDÜRÜ DOKÜMAN
- INTERNATIONALE KONFERENZ „A SECULAR AGE OR A POSTSECULAR CONSTELLATION?
- SUPPLEMENTARY FILE 2 STUDY COSTS RECEIPTS ARE AVAILABLE FOR
- ORDEN FORAL 472015 DE 13 DE OCTUBRE (MODELO 591)
- AJUNTAMENT DE LES VALLS DE VALIRA (ALT URGELLLLEIDA) ACTA
- NOTAS DE PRENSA FEBRERO 2013 NOTA FECHA TEMA
- ILMO(A) SR(A) DD COORDENADOR DO PROGRAMA DE PÓSGRADUAÇÃO EM
- NORMATIVA DE CERTIFICACIÓN DE LA CALIDAD DE CONTENIDOS DIGITALES
- DATOS PARA INICIALIZAR UN IMPRESOR FISCAL LOS DATOS
- LONG BEACH POPCORN PRESENTED AT THE EUROPEAN JUGGLING CONVENTION
- REFERAT FRA 29 MØDE BAR UNDERVISNING & FORSKNING TORSDAG
- CATALINA FOOTHILLS HOME OWNERS ASSOCIATION 8 BOARD OF DIRECTORS
 WWWGOVUK FOI 91840 JULY 2014 FREEDOM OF INFORMATION REQUEST
WWWGOVUK FOI 91840 JULY 2014 FREEDOM OF INFORMATION REQUEST MODEL DE SEGURETAT 10042008 – VERSIÓ 10 PASQUAL FLORES
MODEL DE SEGURETAT 10042008 – VERSIÓ 10 PASQUAL FLORESEVALUACION DE IMPACTO AMBIENTAL DEC 497709 GOB GUIA PARA
UNDANGUNDANG NO 4 TAHUN 1992 TENTANG PERUMAHAN DAN PERMUKIMAN
 LUMBALGIA ¿QUÉ ES LA LUMBALGIA? ES UN
LUMBALGIA ¿QUÉ ES LA LUMBALGIA? ES UNthe Thomas Wolfe Scholarship the Application (please Copy and
MARÍA JESÚS PÉREZ IBÁÑEZ Mª J PÉREZ IBÁÑEZ
 INVITACIÓN ANUAL DEL CONSEJO FEDERAL AL CUERPO DIPLOMÁTICO ACREDITADO
INVITACIÓN ANUAL DEL CONSEJO FEDERAL AL CUERPO DIPLOMÁTICO ACREDITADO1 ZÁKLADNÍ EKONOMICKÉ POJMY OBSAH POTŘEBY PROSTŘEDKY K USPOKOJOVÁNÍ
PLS4 GUIDELINES THE SPANISH EDITITION OF THE PLS4 IS
137 MĂNCRED ÎN EL ORICE SAR ÎNTÂMPLA 1 MĂNCRED
ORDENANZA REGULADORA DEL CEMENTERIO MUNICIPAL DE BATERNO TITULO I
MERCOSURCMCDEC N° 798 MECANISMO CONJUNTO DE REGISTRO DE COMPRADORES
 BOŻENA BEDNAREKMICHALSKA BIBLIOTEKA UNIWERSYTECKA W TORUNIU PRAWO AUTORSKIE I
BOŻENA BEDNAREKMICHALSKA BIBLIOTEKA UNIWERSYTECKA W TORUNIU PRAWO AUTORSKIE IEL H CONGRESO DEL ESTADO DE COLIMA EN SESIÓN
DYFFRYN NANTLLE – A LANDSCAPE OF NEGLECT NANTLLE
 ASSEMBLY NO 2360 STATE OF NEW JERSEY 213TH LEGISLATURE
ASSEMBLY NO 2360 STATE OF NEW JERSEY 213TH LEGISLATUREAUTOS AL JUZGADO DE LO SOCIAL
 ESTUDIANDO LA BIODIVERSIDAD UN MARCO PARA EL MONITOREO MEDIOAMBIENTAL
ESTUDIANDO LA BIODIVERSIDAD UN MARCO PARA EL MONITOREO MEDIOAMBIENTAL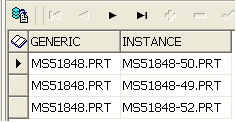 REMOVING INSTANCES FROM FAMILY TABLES IN PDMLINK TABLE
REMOVING INSTANCES FROM FAMILY TABLES IN PDMLINK TABLE
