DIAGNOSTIC TESTS WHAT YOU NEED TO KNOW IN ORDER
DIAGNOSTIC D’ACCESSIBILITÉ ET DE SÉCURITÉ LATRINEDIAGNOSTICO DE LA EMPRESA Y SU ENTORNO
UNIDAD DE NEURORRADIOLOGIA DIAGNOSTICA Y TERAPEUTICA
1 0TH FRONTIERS IN LOW TEMPERATURE PLASMA DIAGNOSTICS KERKRADE
1 KULTIVAČNÍ DIAGNOSTICKÉ METODY KULTIVAČNÍ METODY PATŘÍ K MODERNĚJŠÍM
11 GUÍA DE REFERENCIA DEL SISTEMA DE DIAGNOSTICO DE
Sensitivity describes the proportion of animals with disease that have a positive test
Diagnostic Tests: What You Need to Know in Order to Interpret the Results Obtained from Them
General Properties upon which a Diagnostic Test is Evaluated
Sensitivity and Specificity of a Diagnostic Test
Predictive Value of a Diagnostic Test
Estimating True Prevalence of Disease from Diagnostic Test Results
Screening versus Confirmatory Diagnostic Test
Multiple Diagnostic Tests Performed Serially
Multiple Diagnostic Tests Performed Simultaneously
General Properties upon which a Diagnostic Test is Evaluated
Diagnostic tests are evaluated on the following general properties:
Reliability
Repeatability
Reproducibility
Accuracy
Validity
The reliability of a diagnostic test is the degree to which using the same test gives similar results when it is repeated. The repeatability (sometimes also referred to as precision) of a diagnostic test is defined in terms of the degree of agreement between sets of observations made on the same individuals by the same observer. Thus, repeatability is a characteristic of a reliable test. Reproducibility of a test is defined in terms of agreement between sets of observations made on the same individuals by different observers. Accuracy of a test is measured by the proportion of animals correctly identified or classified as diseased or healthy by the test. Keep in mind accuracy is not synonymous with repeatability. A test can be repeatable without being accurate, but it cannot be accurate without being repeatable. The validity of a diagnostic test measures how well a test reflects the true disease status of an animal. Home
Innate Sensitivity and Specificity of a Diagnostic Test Affects its Validity
An assay is considered ‘validated’ if it consistently produces test results that identify animals as being positive or negative for the presence of a substance (e.g. antibody, antigen, organism) in the sample (e.g. serum) being tested and, by inference, accurately predicts the infection status of the tested animals with a predetermined degree of statistical certainty (confidence). Inferences based on these test results can be made about the infection status of the animals. The process of validating an assay is the responsibility of researchers and diagnosticians. The initial development and optimization of an assay, by a researcher, may require further characterization of the performance of the assay by laboratory diagnosticians before field use. Keep in mind that the specific criteria required for assay validation of an infectious disease are elusive and that the process leading to a validated assay is not standardized. Factors that influence the capacity of the test result to accurately infer the infection status of the host are diagnostic sensitivity (Sn), diagnostic specificity (Sp), and prevalence of the disease in the population targeted by the assay.
Diagnostic sensitivity (Sn) and diagnostic specificity (Sp) of a test are calculated relative to test results obtained from reference animal populations of known infection/exposure status to a specific disease agent. Diagnostic sensitivity describes the proportion of animals with disease that have a positive test result. Diagnostic specificity describes the proportion of animals free of a disease that have a negative test. The degree to which the reference animals represent all of the host and environmental variables in the population targeted by the assay has a major impact on the accuracy of test result interpretation (accuracy is discussed in greater detail below) and applicability of this test in this population. For example, experienced diagnosticians are aware that an assay which has been validated using samples from northern European cattle may not give valid results for the distinctive population of cattle in Africa (but it may be the only test).
The capacity of a positive or negative test result to accurately predict the infection status of the animal is a key objective of assay validation. This capacity is not only dependent upon a highly precise and accurate assay and carefully derived estimates of Sn and Sp (may not be available), but is also strongly influenced by the prevalence of the infection in the targeted population. Without a current estimate of the disease prevalence in that population, the interpretation of a positive or negative test result will be compromised.
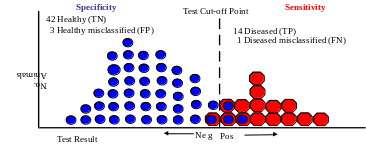
When diagnostic tests are dichotomized into ‘positive’ or ‘negative’, a cut-off point is required. Cut-off points have been determined in several ways. Visual inspection of the frequency distributions of the test results for infected and uninfected animals has been used. The frequency distributions for infected and uninfected animals typically indicate an overlapping region of assay results (the perfect test with no overlap, yielding 100% diagnostic Sn and 100% diagnostic Sp, rarely—if ever—exists). The cut-off is placed at the intersection of the two distributions. This method has the advantage of being simple and flexible, and requires no statistical calculations or assumptions about the normality of the two distributions. Another way to determine a cut-off point is to arbitrarily place it two or three standard deviations greater than the mean of the test values of the unaffected individuals. This approach fails to consider the frequency of disease and the distribution of test results in diseased individuals, and ignores the impact of false-positive and false-negative errors. Another approach is one that identifies 95% of individuals with disease as being test-positive. This ignores the distribution of test results in unaffected individuals, the prevalence of the disease, and all consequences except those that are due to false-negative error. Alternatively, the value that minimizes the total number or total cost of misdiagnoses can be selected. The optimum cut-off point also depends on the frequency distribution of the test variable in the healthy and diseased population, which may be complicated. A cut-off point can also be established by a modified receiver-operator characteristics (ROC) analysis. For more information on ROC analysis, follow this link.
When a cut-off point is identified, there is then clearly an inverse relationship between sensitivity and specificity in a particular test. Individuals for whom the assays value is to the right of the cut-off point are classified as diseased (assuming that the diseased animals have a higher test results than the non-diseased animals), typically a combination of truly diseased animals (true positive; TP) and non-diseased (healthy) animals mis-classified as diseased (false positive; FP). This is the sensitivity established for the test [with a sensitive test, the proportion (prevalence) of truly diseased animals will be higher in the group tested positive than in the initial population of animals to be tested). Individuals for whom the assay’s value is to the left of the cut-off point are classified as healthy, typically a combination of truly non-diseased (healthy) animals (true negatives; TN) and diseased animals mis-classified as healthy (false negative; FN), again the post test proportion (prevalence) of non-diseased animal will be higher than the proportion in the pretest population).. This is the specificity established for the test. If fewer false positives are required, the cut-off point is moved to the right; Diagnostic specificity of the test increases and diagnostic sensitivity decreases. However, if fewer false negatives are required, the cut-off point is moved to the left; Diagnostic sensitivity increases and diagnostic specificity decreases.
Calculation of sensitivity and specificity requires an independent, valid criterion—also termed a ‘gold standard’—by which to define an animal’s true disease status. The diseased and healthy animals to which the ‘gold standard’ is applied should be representative of the population in which the test is to be applied. Thus, a test is conducted in the general population, and so the ‘gold standard’ should be applied to a sample of diseased and healthy animals drawn from this population. In contrast, a clinical diagnostic test is run on animals for which there is usually already evidence of disease where the prevalence of the disease is higher, and the test needs to distinguish between animals with the relevant condition (the ‘diseased’ animals) and those animals with other diseases in your differential disease list (the ‘healthy’ animals). It follows that the choice of a specific test with a given sensitivity and specificity may be different when it is applied as a test than when it is used as a diagnostic test in a veterinary clinic due to the higher disease prevalence rate in clinically ill animals.
The following example is presented to illustrate the diagnostic sensitivity (Sn) and diagnostic specificity (Sp) of a test in a general population of animals and how they are influenced by the choice of the cut-off point. In this example, a 60 head beef herd has a known 25% prevalence of disease “X” (45 healthy animals; 15 diseased animals).

= 15 Diseased
 =
45 Healthy
=
45 Healthy

Test “Y” is conducted looking for disease agent “X” in a sample of blood drawn from each animal in the herd (generally higher Sn and lower Sp). The disease status of each animal is known. Each animal is classified as diseased or healthy based on the following cut-off point of test “Y” as established by the laboratory conducting the test:

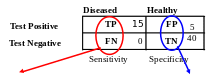
TP = True positive
FP = False positive
TN = True negative
FN = False negative
Sn = TP / (TP + FN) = 14/(14+1) = 93.33% Sp = TN / (TN + FP) = 42/(42+3) = 93.33%
Let’s assume that the laboratory wants to improve the sensitivity of the test in order to identify all diseased animals, as would be the case when attempting to eradicate a disease. In order to accomplish this goal, the test cut-off point must be shifted to the left. The example below shows that the test cut-off point has been moved to the left sufficiently to result in a test that has 100% sensitivity.

Sn = TP / (TP + FN) = 15/(15+0) = 100.00% Sp = TN / (TN + FP) = 40/(40+5) = 88.89%
Please note that the effort to improve the sensitivity of test “Y” has eliminated the number of false negatives but the trade-off to this action is that the number of false positives increases, i.e. the number of healthy animals misclassified as diseased increases.
Let’s consider a different scenario. Assume that the laboratory wants to improve the specificity of the test in order to identify all healthy animals. In order to accomplish this goal, the test cut-off point must be shifted to the right. The example below shows that the test cut-off point has been moved to the right sufficiently to result in a test that has 100% specificity.


Sn = TP / (TP + FN) = 10/(10+5) = 66.67% Sp = TN / (TN + FP) = 45/(45+0) = 100.00%
Please note that the effort to improve the specificity of test “Y” has eliminated the number of false positives but the trade-off to this action is that the number of false negatives increases, i.e. the number of diseased animals misclassified as uninfected increases. Home
As mentioned previously, the accuracy of a diagnostic test is measured by the proportion of animals correctly identified or classified as healthy (true negative; TN) or diseased (true positive; TP) by the test, i.e. Accuracy = (TN + TP) / N, where N is the number of animals sampled. In the examples given above, the accuracy of the test at each test cut-off point is:
Original test cut-off point for test “Y”:
Accuracy = (TN + TP) / N = (42 + 14) / 60 = 93.33%
Test cut-off point moved to the left for a more sensitive test “Y”:
Accuracy = (TN + TP) / N = (40 + 15) / 60 = 91.67%
Test cut-off point moved to the right for a more specific test “Y”:
Accuracy = (TN + TP) / N = (45 + 10) / 60 = 91.67% Home
Predictive Value of a Diagnostic Test
Remember, diagnostic sensitivity (Sn) and diagnostic specificity (Sp) are innate characteristics of a test and (for a defined cut-off point) do not vary. Thus, as a veterinary epidemiologist, you do not have control over the diagnostic Sn and diagnostic Sp of a test itself unless, of course, you were the person that developed the test or you convince laboratory personnel that are running the test to adjust the cut-off point to make it more sensitive or specific for your situation. Interestingly, employing multiple diagnostic tests is another way to improve overall diagnostic Sn or diagnostic Sp, depending on which one is your focus.
Consequently, the Sn and Sp of a test does not help you decide what a test result means when the disease status of an animal is unknown, without knowledge of the disease prevalence in that population. Under field conditions, what you really want to know is the probability that an animal, ‘positive’ according to your test, is actually positive (i.e. animal is truly diseased), given that animals that have been sampled are from a herd of unknown disease status. Likewise, if your test gives a ‘negative’ result, you want to know what the probability is that the animal is truly negative (i.e. animal is not infected with the disease agent of concern). The positive and negative predictive value of a test helps understand and interpret test results from a herd with unknown disease status.
Even though you have no control over the Sn and Sp of a test, they along with amount (prevalence) of disease in the herd being tested do affect predictive value. Positive Predictive Value or PPV (also referred to as predictive value positive or PVP) estimates the probability that the animal is diseased, given that a test is positive. Negative Predictive Value or NPV (also referred to as predictive value negative or PVN) estimates the probability that the animal is not diseased (healthy), given that a test is negative. The results of the diagnostic test divide the pre-test population into two groups: test positive group and test negative group and changes the proportion to diseased/non-diseased animals in each post-test group.
Figure 1 and Table 1 below illustrate the relationship between PPV and NPV of a diagnostic test (with a given Sn and Sp) and the associated number of true positives (TP), true negatives (TN), false positives (FP), and false negatives (FN) that occur as the prevalence of disease within the herd changes.
Test
Sn = 95.00% Test
Sp = 95.00%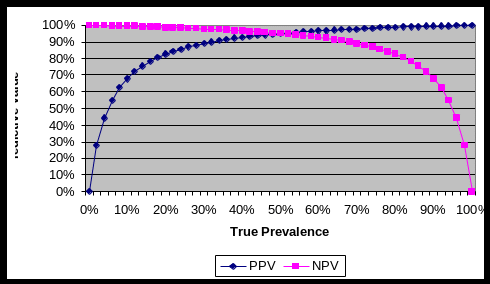
Figure 1. Relationship of positive predictive value (PPV) and negative predictive value (NPV) with changes in prevalence of disease within a herd or flock that is screened with a given diagnostic test of specified diagnostic sensitivity (Sn) and diagnostic specificity (Sp).
Table 1. The relationship between PPV and NPV and the associated distribution of TP, FP, TN, and FN cases as prevalence of disease changes within a herd of 1,000 animals when tested with a test of high sensitivity (.95) and high (.95) specificity.

You should note from looking at both the graph and table that as the prevalence of disease within a herd decreases, the positive predictive value (PPV) of the diagnostic test with a defined Sn and Sp also decreases. In practical terms, what this means is that as prevalence of disease decreases, out of the ‘positive’ animals identified by the test, an increasingly larger number of them will be false positives (FP) and fewer true positives (TP). In contrast, the negative predictive value (NPV) of an initial test increases as the prevalence of disease within a herd decreases. In practical terms, what this means is that as prevalence of disease decreases, out of the ‘negative’ animals identified by the test, an increasingly larger number of them will be truly negative (TN) and fewer and fewer will be false negatives (FN).
Just the opposite occurs as the prevalence of disease within a herd increases; PPV increases and NPV decreases. In practical terms, what this means is that as prevalence of disease increases, out of the ‘positive’ animals identified by the test, an increasingly larger number of them will be truly positive and out of the ‘negative’ animals, an increasingly larger number of them will be false negatives.
In summary, PPV and NPV have an inverse relationship as prevalence of disease changes. Home
Estimating True Prevalence of Disease from Diagnostic Test Results
When testing a herd or flock of unknown disease status, the proportion of ‘positive’ animals out of all animals tested is a measure of test prevalence (also known as apparent prevalence, Papparent) of disease, but not the true prevalence of disease within a herd or flock. However, if diagnostic sensitivity (Sn) and diagnostic specificity (Sp) of the test is known, the true prevalence of disease, Ptrue, can be calculated using Papparent according to the following formula:
Ptrue = (Papparent + Sp – 1) / (Sn + Sp – 1)
For example, if 40% of a herd of 100 animals is ‘positive’ for disease “X” when tested using a test with .90 Sn and .95 Sp, the true prevalence of disease is estimated to be:
Ptrue = (.4 + .95 – 1) / (.9 + .95 – 1) = .35 / .85 = .4117 or 41.17%
In this example, the calculation (41.7%) for true prevalence of disease actually represents a mean. The true prevalence of disease in this herd lies within a range of values. A confidence interval (CI) can be calculated, which provides a way of expressing the range over which a value is likely to occur. Although any range can be used, the 95% CI is most commonly used in the veterinary literature. What does 95% CI means? You are “95% confident that over many samplings, the mean prevalence of disease “X” in this herd will lie in this interval”. Alternatively, it means that if you performed 100 samplings of the same number of animals, 95 of the herd’s true prevalence values are predicted to lie in this interval and 5 will not. Why? Because the herd prevalence is an estimate of the population's mean, which has a 95% probability of being within this interval.
In order to calculate a 95% CI, the mean, variance, and standard deviation of disease prevalence (also referred to as standard error of the proportion) must be available. In the example above:
Again, the true prevalence of disease (41.7%) calculated above is considered to be the mean.
The variance of disease prevalence equals [p(1-p)/n], where p is the proportion of diseased individuals and n is the sample size. Thus, the variance is (.417 X .583)/100 or 0.00243.
T he
standard error of the proportion equals the square root of the
variance: √0.00243 = 0.049
he
standard error of the proportion equals the square root of the
variance: √0.00243 = 0.049
The 95% CI for disease “X” = Ptrue ± 1.96 (standard error of the proportion)
CI = .417 ± 1.96 X 0.049
= .417 ± .096
= .321 to .513 (Instead of 41.7%, 95% confident that true prevalence of disease “X” is between 32.1% and 51.3%) Home
Screening versus Confirmatory Diagnostic Test
In a typical surveillance scenario dealing with an outbreak of disease, a ‘screening test’ refers to the testing of a wide cross-section of a population of apparently healthy individuals in order to detect infection or subclinical disease. The test used is usually not aimed at establishing a definitive diagnosis. Rather, the aim is to separate individuals that probably have a disease from those that probably do not. Thus, it is very important for the screening test to be of high diagnostic sensitivity (Sn). The diagnostic specificity (Sp) of the screening test can be compromised for the sake of achieving high diagnostic sensitivity (Sn). Alternatively, the positive predictive value of a screening test can be improved by sampling only high risk populations, i.e. targeted surveillance of populations likely to have a high rate of infection or disease. Remember, PPV and prevalence of disease have a positive relationship—as prevalence of disease increases so does the PPV of a test and as prevalence of disease decreases so does PPV of the test.
As the name implies, the aim of a ‘confirmatory test’ is to confirm results derived from other test methods, such as a screening test. Since the reason for using a confirmatory test is most often to confirm that an individual is diseased, a confirmatory test is typically chosen that has high diagnostic specificity (Sp)—reduces the number of false positives—since the objective is to confirm a positive result, i.e. confirm presence of disease in an individual. In general, a confirmatory test is typically more difficult to perform and takes longer to perform than a screening test, is less readily available within a laboratory system because of additional expertise needed to perform the test, and is more expensive than more commonly used screening tests. A confirmatory test could actually be a ‘gold standard’.
However, if the objective is to establish freedom from disease in the individuals being tested, a confirmatory test would be run instead on all negative animals. This test should be one that possesses high diagnostic sensitivity (Sn)—reduces the number of false negatives. Home
Employing Multiple Diagnostic Tests
Multiple diagnostic tests performed serially
The objective of using multiple tests is to improve predictive value, either positive- or negative-wise. One approach is to use a series of one or more confirmatory tests after a screening test has been used to initially categorize individuals as positive (‘series positive’ testing regime) or negative (‘series negative’ testing regime). This is the likely way in which a disease outbreak is handled in the field. In the case of individuals classified as positive, any confirmative tests used should be a different biological type of test than that of the screening test and the innate specificity of the test should be greater, if at all possible, in an effort to decrease the probability of a false positive occurring. An example for serial testing is when light bulbs are connected in series and all bulbs must work in order for all the lights to shine—all or nothing. An animal is deemed to be infected with the disease agent in question if it is ‘positive’ to all tests (Table 2). Otherwise, the animal is deemed to be uninfected. ‘Serial positive’ testing is essentially asking the animal to prove that it is affected by the disease.
Table 2. Examples of probable disease status in different animals based on ‘series positive’ testing.

+ = positive test - = negative test Non-diseased = not infected Diseased = infected
The purpose of ‘series negative’ testing is to rule out a disease. Ideally, confirmatory tests should be a different biological type of test than that of the screening test and the innate sensitivity of the definitive test should be greater, if at all possible, in an effort to decrease the probability of a false negative occurring. Decreasing the probability of a false negative occurring will decrease the likelihood that a diseased animal will be missed. An animal is deemed to be uninfected with the disease agent in question if it is ‘negative’ to all tests (Table 3). Otherwise, the animal is considered to be diseased if at least one of the tests is positive. ‘Series negative’ testing is essentially asking the animal to prove that it is healthy.
Table 3. Examples of probable disease status in different animals based on ‘series negative’ testing.

+ = positive test - = negative test Non-diseased = not infected Diseased = infected
In summary, ‘series positive’ testing:
Used to rule in a disease
Improves the overall diagnostic specificity (Sp) and positive predictive value (PPV) of the combined tests—few false positives and more true negatives are identified (see example in Figure 2)
The greatest predictive value is a positive test result
Decreases the overall diagnostic sensitivity (Sn) and negative predictive value (NPV) of the test regime—more false negatives and fewer true positives are identified (see example in Figure 2)
Increases the risk of missing a diseased animal
Most useful if rapid assessment is not necessary, i.e. when time is not critical such as with test and removal programs.
Also useful to employ when there is an important penalty for false positive results.
 Population
size: 2,000 Hd
Population
size: 2,000 Hd
Expected prevalence: 20%
Sensitivity (Sn) Test 1: 98.00%
Specificity (Sp) Test 1: 95.00%
Test
is higher Sp
 Specificity
(Sp) Test 2: 99.00%
Specificity
(Sp) Test 2: 99.00%

Results from re-testing all positive individuals (‘series positive’):
Sp increased from 95.00% to 99.94% for the combined tests and PPV increased from 83.05%
to 99.74% for the combined tests; Sn decreased from 98.00% to 95.00% for the combined tests
and NPV decreased from 99.48% to 98.76%
Figure 2. Example of ‘series positive’ results obtained for combined test Sn and Sp and combined PPV and NPV when animals in a herd that are positive to a screening test are re-tested with a more diagnostic specific confirmatory test.
In summary, ‘series negative’ testing:
Used is to rule out a disease
Improves the overall diagnostic sensitivity (Sn) and negative predictive value (NPV) of the combined tests—few false negatives and more true positives are identified (see example in Figure 3)
The greatest predictive value is a negative test result
Decreases the overall diagnostic specificity (Sp) and positive predictive value (PPV) of the test regime—more false positives and fewer true negatives are identified (see example in Figure 3)
Decreases likelihood of missing a disease
Most useful when a rapid assessment of disease status of individual (diseased) animals is needed or in emergency situations
Also useful to employ in situations when there is an important penalty for missing a disease (i.e. false negative results).
Population size: 2,000 Hd
Expected prevalence: 20%
Sensitivity (Sn) Test 1: 98.00%
Specificity (Sp) Test 1: 95.00%
Test
is higher Sn
Sensitivity
(Sn) Test 2: 99.00%
Specificity (Sp) Test 2: 90.00%
Results from re-testing all negative individuals (‘series negative’):
Sn increased from 98.00% to 100.00% for the combined tests and NPV increased from 99.48%
to 100.00% for the combined tests; Sp decreased from 95.00% to 85.50% for the combined tests
and PPV decreased from 83.05% to 63.29%
Figure 3. Example of ‘series negative’ results obtained for combined test Sn and Sp and combined PPV and NPV when animals in a herd that are negative to a screening test are re-tested with a more diagnostic sensitive confirmatory test. Home
Multiple diagnostic tests performed simultaneously
Although probably less likely to do in an outbreak situation due to cost constraints, another method of using multiple tests is to initially apply two or more tests simultaneously to all individuals being sampled. When tests are used in this manner, the resultant sensitivity and specificity are dependent on the way the results are interpreted.
When a high sensitivity is required, parallel interpretation is employed. An individual must be negative to both tests to be considered healthy (uninfected). Otherwise, an individual is considered positive if it reacts positively to one or the other or both tests. Using the light bulb analogy, there will be light from one bulb even if the other bulbs are defective. This increases the sensitivity but tends to decrease the specificity of the combined tests. This makes intuitive sense since it gives a diseased animal the greatest opportunity to react positively.
When a high specificity is required, series interpretation is employed. An individual must be positive to both tests to be considered positive (diseased), otherwise the individual is deemed to be healthy (uninfected). Specificity increases but sensitivity decreases because the likelihood of a diseased individual giving a negative response to both tests is less than the likelihood of it giving a positive result to both, or positive response to the first and negative to the second or vice versa.
In general, the greater the number of tests involved, the greater the increase in sensitivity or specificity of the combined tests depending upon the method of interpretation. To identify the optimal classification, i.e. minimizing the overall misclassification rate, more elaborate techniques such as discriminant analysis are required. Home
Scenario 1:
When you don’t know the disease status of the herd or flock [i.e. number of infected animals versus number of uninfected animals (pretest prevalence)] prior to testing, but want to know if disease is present, is it better to use a test of high diagnostic sensitivity or high diagnostic specificity?
The default answer would be to use a highly sensitive test, if the goal of testing is first and foremost to detect disease (identify the first case) in a general population of animals. Please note that this statement is made in the context of the cut-point of the test. Remember, to get high sensitivity on a test, the cut-point is moved to the left, in order to get all infected animals, but some uninfected animals are also identified as infected (FP) because it is rare to have a 100% sensitive test. Also keep in mind that if you are testing animals for the presence of a ‘rare’ disease (≤ 5-10% in-herd or flock prevalence of disease) the number of FP animals may, in some instances be nearly as large as the number of TP animals (remember the discussion above on positive predictive value of a test as influence by prevalence of disease?). Screening tests are not usually intended to provide definitive diagnoses but are designed to detect as many cases as possible. If there is a reason to test all positive animals with a follow up test, with the goal to identify as many truly positive animals as possible, it should be of higher innate Sp than the initial screening test in order to eliminate as many false positives as possible (see discussion on testing in serial below).
Additional impetus for using a highly sensitive test over a highly specific test is a situation where there is the potential to have adverse consequences (e.g. when the cost of a false negative exceeds that of a false positive) for the failure to detect a disease, particularly a highly infectious and contagious disease.
Scenario 2:
What about the situations where you want to demonstrate absence of (freedom from) a disease in a general animal population, e.g. release a herd or flock from quarantine?
The default answer would be to use a highly specific screening test. Again, please note that this statement is made in the context of the cut-point of the test. Remember, to get high specificity on a test, the cut-point is moved to the right, in order to get all uninfected animals (TN), but some infected animals are also identified as uninfected (FN) because it is rare to have a 100% specific test. However, even in a ‘rare’ disease situation (≤ 5-10% in-herd or flock prevalence of disease) the number of FN animals tend to be few; most are TN animals (remember the discussion above on negative predictive value of a test as influence by prevalence of disease?). To reiterate, in testing the herd or flock with a highly specific screening test, both TN and FN animals will be in the pool of ‘negative’ animals—but the higher the Sp the fewer the FNs. Conversely, with the high Sp, there will by more FPs in the group of test positive animals. When a follow up test is used, with the goal to identify as many truly negative animals as possible, it should be of higher innate Se than the initial screening test in order to eliminate as many false negatives as possible (see discussion on testing in parallel below).
A highly specific test will also identify ‘positive’ animals but with a higher proportion of FPs in the group. These animals are eliminated from the herd or flock without additional testing, since the goal is to demonstrate freedom from disease.
Scenario 3:
What about the situations where you want to rule-out or rule-in a disease in an animal?
While the utility of a highly sensitive test is first and foremost to identify infected animals in a herd, a highly sensitive test can also be used to rule-out a disease early in a diagnostic work-up of an ill animal, especially in a rare (low prevalence) disease. The rationale behind using a highly sensitive test in this manner is as follows: when dealing with a clinically ill animal, after testing, a ‘positive’ could indicate true disease (TP) or misclassification as diseased (FP). Further testing will be required to delineate whether the animal is truly infected or not with the disease agent in question. However, if the animal is ‘negative”, it is quite likely that the animal is indeed uninfected, especially if the disease is rare, because there are fewer FNs in the test negative group, therefore, a negative test result rules out the disease. Remember, a 100% sensitive test will have no false negatives, so if the animal is ‘negative’ then the probability is high the disease agent in question is not present. In summary, in situations where a low prevalence of disease “X” is expected, a negative result from a highly sensitive test provides evidence for ruling-out the disease. The acronym “SnNout” may be helpful to remember the meaning of a negative test: Highly Sn test, Negative, Rule-out the disease.
Conversely, a highly specific test is desirable to rule-in a disease early in diagnostic work-up of an ill animal. The rationale behind using a highly specific test in this manner is as follows: when the animal is classified as ‘negative’ upon testing, you don’t necessarily know without further testing if it is truly uninfected (TN) or misclassified as uninfected (FN), but if the animal is ‘positive’ on the test, it is quite likely that the disease agent in question is present, especially where the disease prevalence is high because there are few FPs. Again, keep in mind this statement is made in the contest of cut-point. High specificity in a test is gained by moving the cut-point to the right. Very few false positives (remember, a 100% specific test will have no false positives—see example above) will be present, so if the animal is ‘positive’ then it has a high probability of being infected with the disease agent. In summary, in situations where a high prevalence of disease “X” is expected, a positive result from a highly specific test provides evidence for ruling-in the disease. The acronym “SpPin” may be helpful to remember the meaning of a positive test: Highly Sp test, Positive, Rule-in the disease.
These series of questions make the point, hopefully, that diagnostic sensitivity and diagnostic specificity of a test may be different when it is applied as a screening test in the field than when it is used as a diagnostic test on a clinically ill animal in a veterinary clinic. Home
Jacobsen RH. Validation of serological assays for diagnosis of infectious diseases. Rev Sci Tech Off Int Epiz 1998;17(2):469-486. The link to this article is:
Thrusfield M. Diagnostic testing. In: Thrusfield M, ed. Veterinary Epidemiology. 2nd ed. London: Blackwell Science Ltd. 1995;266-285. The link to this article is:
Smith RD. Statistical significance. In: Smith RD, ed. Veterinary Clinical Epidemiology. 3rd ed. Boca Raton, FL: CRC Press. 2006;137-161.
Martin SW, Meek AH, Willeberg P. In: Martin SW, Meek AH, Willeberg P, eds. Veterinary Epidemiology—Principles and Methods. Ames, IA: Iowa State University Press. 1987;48-76.
18 THE MISUSE OF UNIDIMENSIONAL TESTS AS A DIAGNOSTIC
19 PREDIAGNOSTIC COPPER AND ZINC BIOMARKERS AND COLORECTAL CANCER
2 DIAGNOSTICKÉ METODY A TECHNIKY PEDAGOGICKÁ DIAGNOSTIKA POUŽÍVÁ NEJEN
Tags: diagnostic tests:, m. diagnostic, diagnostic, order, tests
- CONVEYOR STATION – EXERCISE 8 SORTING WORKPIECES CONVEYOR STATION
- FOOD & HEALTH STRATEGY FOR SOUTH GLOUCESTERSHIRE 2009 –
- INSTRUCTIONS FOR WEEKLY SCHEDULE THIS EXERCISE WILL HELP YOU
- FABRISEDAS PROYECTA CRECER 18 HTTPWWWLAREPUBLICACOMCONOTICIAPHP?IDNOTIWEB25800&IDSUBSECCION70&TEMPLATENOTICIA&FECHA200412241159PM LA FIRMA DEL
- STRUČNÉ NETECHNICKÉ SHRNUTÍ ÚDAJŮ UVEDENÝCH V ŽÁDOSTI ELEKTRÁRNA
- APPENDIX A APPLICATION FOR ONLINE ACCESS TO MY MEDICAL
- 4 PSII4314220171311 PANI ANNA MARIA KULCZYŃSKA DYREKTOR POWIATOWEGO CENTRUM
- POILSIO PERTRAUKĖLĖS PRATIMAI 1 AKIŲ AKOMODACIJA STEBĖKITE DAIKTĄ
- HONORABLE CÁMARA DE DIPUTADOS SECRETARÍA DE COMISIONES CORRIENTES SEÑOR
- AUGUST 2005 CICTE INFORME 26 COUNTER TERRORISM ACTIVITIES EU
- N DATA PURI PURA PEMANDIAN SUMBER MATA AIR DESA
- UKRAINE (UPDATE 31 JAN 06) OP 2 BIOLOGICAL
- TYPES OF COMMON IONIC REACTION SYNTHESIS REACTIONS ALSO CALLED
- HTTPWWWMICROSOFTCOMNZCASESTUDIESDIRECTORYPRECEPTASPX PRECEPT SYSTEMS SOLUTION OVERVIEW ONE BUTTON CLICK AND
- A LAMPIRAN IIF KEPUTUSAN KEPALA DINAS PENANAMAN MODAL
- 137 FACULTAD DE CIENCIAS APLICADAS ESCUELA DE INGENIERIA
- PRIMER MINI DOMAĆEG (AST VERZIJA) – DRUGI DEO SEMANTIČKA
- SLOVENIAN PRIME MINISTER JANŠA “ITS ABOUT FREEDOM AND JUSTICE!”
- ANEXO III DECLARACION EXPRESA RESPONSABLE DE INGRESOS ECONOMICOS DDÑA
- OSNUTEK ŠT 5 NA PODLAGI ŠESTEGA ODSTAVKA 53 ČLENA
- TEORIK ÇERÇEVESIYLE SAĞLIK EKONOMISI VE TÜRKIYE’YE İLIŞKIN GENEL BIR
- POTOVANJE V IN IZ EU PODROBNEJŠI OPIS 3 IZDAJA
- [O3EVAL185] FUNCIÓN DE USUARIO PARA LA MEDIANA CREATED 08MAR13
- LISTADO DE LIBROS PARA EDUCACIÓN INFANTIL CURSO ACADÉMICO 201415
- ACERCA DE LA EDUCACIÓN INCLUSIVA DEFINIENDO LA EDUCACIÓN
- DIRECTOR OF YOUTH MINISTRY JOB DESCRIPTION PURPOSE OF POSITION
- DETERMINANTES SOCIALES DE LA SALUD DESCRIPCIÓN CURSO TEÓRICO –PRÁCTICO
- 44 BEISPIEL VERBUNDVERTRAG ZWISCHEN DEM VEREIN AUSBILDUNGSGEMEINSCHAFT UND DER
- SCITSDWG33 APÉNDICE II PÁGINA 2 APÉNDICE II REVISIÓN DE
- A CONNECTION 1 INFORM THE PATIENT ON THE TECHNIQUE
 UNIVERSIDAD NACIONAL DANIEL ALCIDES CARRION LP N° 006 –
UNIVERSIDAD NACIONAL DANIEL ALCIDES CARRION LP N° 006 – METODIKA INFORMOVÁNÍ OSOB Z CÍLOVÉ SKUPINY A POSUZOVÁNÍ JEJICH
METODIKA INFORMOVÁNÍ OSOB Z CÍLOVÉ SKUPINY A POSUZOVÁNÍ JEJICH NOTAT TIL STORTINGETS FINANSKOMITÉ FRA FNH DATO 20 JANUAR
NOTAT TIL STORTINGETS FINANSKOMITÉ FRA FNH DATO 20 JANUARKATALOG STANDARDOV STROKOVNIH ZNANJ IN SPRETNOSTI ZA POKLICNO KVALIFIKACIJO
 PTSD-Permission-to-Contact
PTSD-Permission-to-Contact NAME CLASS N EWSIES VIEWING GUIDE DISNEY
NAME CLASS N EWSIES VIEWING GUIDE DISNEYBASEL CONVENTION 2002 COUNTRY FACT SHEET 2009 CROATIA STATUS
BLOQUE DE “RITMO Y EXPRESIÓN III” 1 INTRODUCCIÓN A
DEBE IMPEDIRSE QUE LOS HIJOS SIGAN DESPOJANDO Y DEJANDO
 KRAKÓW DNIA 21 LIPCA 2006 ROKU SZANOWNY PAN DR
KRAKÓW DNIA 21 LIPCA 2006 ROKU SZANOWNY PAN DR EDICIÓN DE TEXTOS CON WORD AL INICIAR WORD APARECE
EDICIÓN DE TEXTOS CON WORD AL INICIAR WORD APARECE OCEAN MARINECANADA APPLICATION FOR OPEN CARGO INSURANCE THIS APPLICATION
OCEAN MARINECANADA APPLICATION FOR OPEN CARGO INSURANCE THIS APPLICATION BEST WESTERN PREMIER HOTEL SLON | SLOVENSKA 34 LJUBLJANA
BEST WESTERN PREMIER HOTEL SLON | SLOVENSKA 34 LJUBLJANAWNIOSEK O NADANIE TYTUŁU „HONOROWY OBYWATEL GMINY WOŁCZYN” WNIOSEK
PROGRAM EDUKACJI ZDROWOTNEJ W LICEUM OGÓLNOKSZTAŁCĄCYM PŁOCKIEGO TOWARZYSTWA OŚWIATOWEGO
THE 24TH ANNUAL BOOK REPORT COMPETITION FOR SECONDARY SCHOOL
 ARBEITSBLATT ZUM THEMA PRODUKTIV VERSTEHENDES SCHREIBEN AUF DER GRUNDLAGE
ARBEITSBLATT ZUM THEMA PRODUKTIV VERSTEHENDES SCHREIBEN AUF DER GRUNDLAGEDEPARTAMENTO TÉCNICO DE REVISIÓN LEGISLATIVA SANTO DOMINGO DN 12
D050311 RECYKLING 0 GENERALNA DYREKCJA DRÓG PUBLICZNYCH OGÓLNE SPECYFIKACJE
FILE KN PAGE 6 SEX OFFENDER AND CRIMES AGAINST
