MATRIX FUNCTIONS 1 WE CAN EASILY DEFINE A NATURAL
QUESTION & ANSWER (Q&A) MATRIX ON IMPLEMENTATION OF2 MATRIX ALGEBRA IN THIS SECTION YOU WILL LEARN
201605-0324-basic-fatigue-management-audit-matrix-bfm
22 122121 GENERAL EDUCATION REPORTING MATRIX CONTACT DR PAULA
4 UK AIDMATCH SCIAF PROGRAMME RISK MATRIX RISK LIKELIHOOD
9 LEASTSQUARES JOINT DIAGONALIZATION OF A MATRIX SET BY
Matrix functions
Matrix functions
1. We can easily define a natural power of a square matrix X as a product:
![]()
For a non-singular matrix, a negative power can be defined as a corresponding positive power of the matrix inverse:
X–n = (X–1)n
or, alternatively, as the matrix inverse of the positive power:
X–n = (Xn)–1
Exercise: Demonstrate that the two definitions are equivalent.
The zeroth power of any matrix is the identity matrix by definition:
X0 = I
Exercise: Demonstrate the following properties of matrix powers:.
XnXm = Xn+m
(Xn)m = Xnm
3. If y is an eigenvector of matrix X: Xy = y, then X2y = XXy = Xy = Xy = 2y. Analogously, for any power: Xny = ny. Therefore, the n-th power of matrix X has the same eigenvectors as the original matrix X, with the corresponding eigenvalues being n. This is also true for any negative power, including the matrix inverse: X–1y = y XX–1y = Xy Xy = (1/)y.
A diagonalizable matrix X can be expressed as follows (similarity transformation):
X = TT–1
where = diag(1,2,...N) is the diagonal matrix of eigenvalues and T is the eigenvector matrix (column by column). Then, for the X2 matrix we obtain:
![]()
where = diag(12,22,...N2). In the case of normal matrices (X†X = XX†), the eigenvectors are orthogonal: T–1 = T†. Analogously, any power Xn can be expressed as follows:
Xn = TnT–1
n = diag(1n,2n,...Nn).
4. If a given real function can be expressed as a Taylor series:
![]()
where
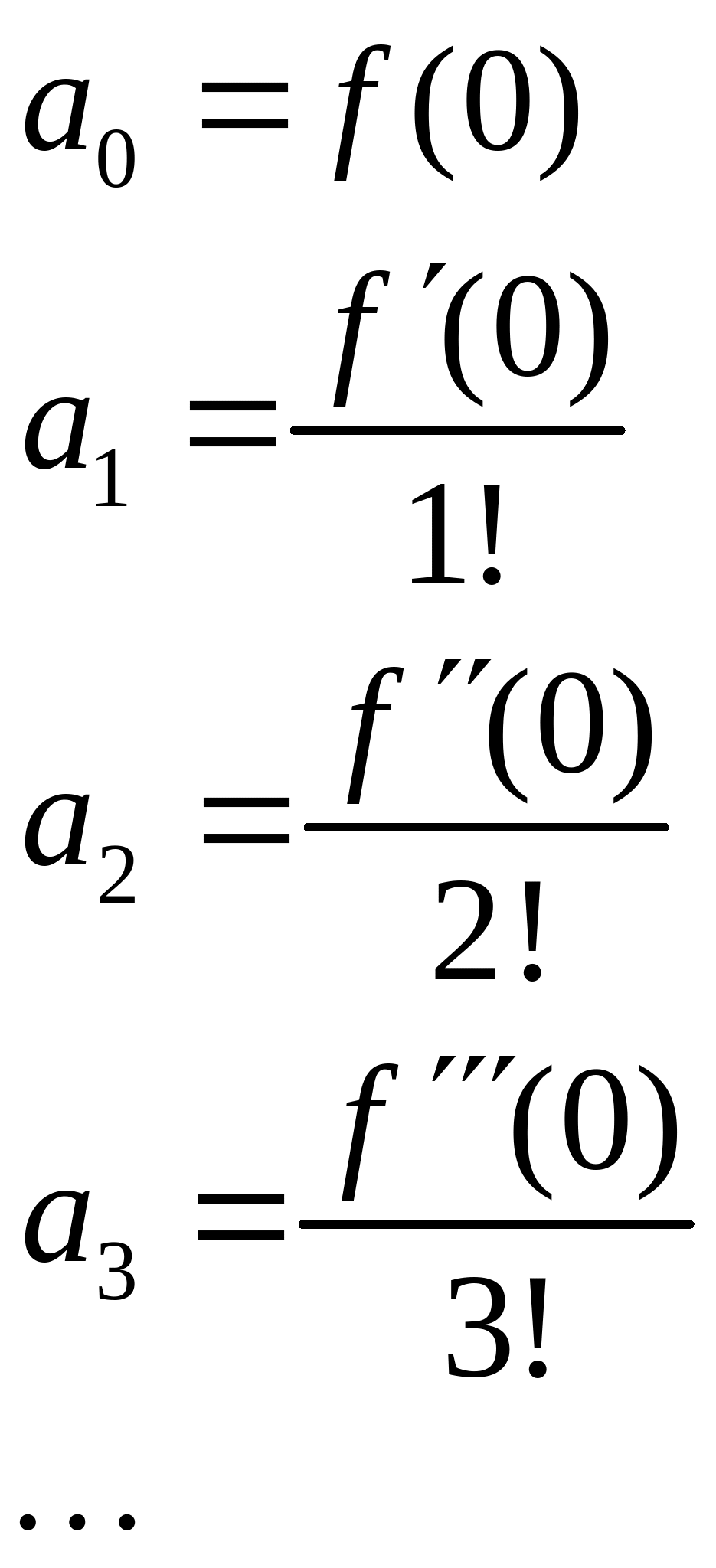
we can construct a similar power series substituting the scalar argument x by a square matrix X:
![]()
This is a definition of function f of a matrix X.
For instance, the exponent of matrix X will be given by the following series:
![]()
5. The above Taylor expansion can be used as such to iteratively compute a matrix function, but for diagonalizable matrices it is usually more efficient to employ the following algorithm:
a. Diagonalize matrix X, obtain the matrix of eigenvectors T and the diagonal matrix of eigenvalues . If X is not a normal matrix, we will also need to invert T. This gives a similarity transformation X = TT–1, where = diag(1,2,...N).
b. The exponent of matrix X is given by the following expression:

The latter formula gives us a non-iterative method of calculating exp(X) through diagonalization. In general, any matrix function can be calculated this way:
f(X) = T diag(f(1), f(2),... f(N))T–1.
Obviously, f(X) has the same eigenvectors as the original matrix X, with the corresponding eigenvalues being f().
6. The square root X1/2 of matrix X is defined through the expression (X1/2)2 = X. The calculation of X1/2 can be also carried out by way of the diagonalization technique:
![]()
Exercise: Demonstrate that the above formula indeed yields X1/2.
6. The inverse square root X–1/2 of matrix X is defined through the expression (X–1/2)2 = X–1. The calculation of X–1/2 can be done analogously:
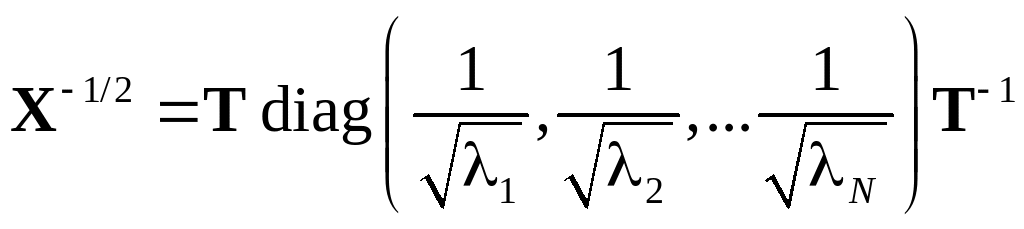
Of course, this is only possible if all eigenvalues are non-zero.
Otherwise, X is singular and X–1/2
does not exist. Note that the functions
![]() or
or
![]() can not be represented by Taylor series. Nevertheless, the
above algorithms work.
can not be represented by Taylor series. Nevertheless, the
above algorithms work.
The inverse square root plays a crucial role in the Löwdin orthogonalization method.
7. Note that if matrix X is Hermitian, all its powers Xn and matrix functions f(X) will be also Hermitian. This refers, in particular, to matrix inverse X–1, matrix square root X1/2, and the inverse square root X–1/2.
ABSTRAK PEMBUATAN ALSIC METAL MATRIX COMPOSOITES DENGAN METODE LANXIDE
ACCOMMODATIONS MATRIX FOR DAILY ACTIVITIES READ WRITE HDWR
ACCOUNTING MATRIX STRANDS CONCEPTUAL PROCESSING REPORTING INTERPRETATION
Tags: define a, natural, functions, easily, define, matrix
- PI0000 PAGE 0 WISCONSIN DEPARTMENT OF PUBLIC INSTRUCTION VERIFICATION
- † LA SEÑORA Dª EMERITA ENRIQUEZ GONZALEZ (VDª DE
- TYPED VARIABLES IN DAVEML TYPED VARIABLES IN DAVEML 717341DOC
- INGLÉS NIVEL PREINTERMEDIO (II) 40 HORAS OBJETIVOS
- POSTA AZKARRAREN ZERBITZUA KONTRATATZEKO EZAUGARRI TEKNIKOEN AGIRIA (ESP X15020)
- ALL THE BROKEN PIECES BY ANN E BURG NAME
- PERIZIA CONTRATTUALE ARBITRATO IRRITUALE DIFFERENZE TERZO APPREZZAMENTO TECNICO TRIBUNALE
- LISTEN A MINUTECOM TELEVISION HTTPWWWLISTENAMINUTECOMTTELEVISIONHTML ONE MINUTE A DAY
- TEXTOS DE SELECTIVIDAD TRADUCIDOS ITEXTOS DE EUTROPIO ESCIPIÓN UN
- CARTA DE PORTE TRANSPORTE BULTOS ENVASES VACÍOS IDENTIFICACIÓN DEL
- 150 NAČINA KAKO BITI DOBAR PREMA MAJCI ]BOSANSKI –
- COORDINACIÓN NERVIOSA HORIZONTALES 19 ES LA ZONA DE FRONTERA
- CANARA BANK PROPOSE TO SHIFT THE MANDI CHOWK MORADABAD
- KONTAKTER FOR FORSIKRINGSSELSKAP FELLES EPOST FORSIKRINGALERISNO TLF 22 54
- CAPÍTULO III EL GRUPO ONCE I EL GRUPO ONCE
- ALLEGATO 3 MODELLO DI FORMULARIO PERIL DOCUMENTO DI
- WOKINGHAM BOROUGH COUNCIL LICENSING ACT 2003 APPLICATION
- A YEAR AT A GLANCE TAYLOR SCHMIDT SUMMER SCHOOL
- HTTPFLAIRFLOW4VSCHTCZ HTTPWWWFLAIRFLOWCOM EVROPSKÝ VÝZKUM BSE (EUROPEAN RESEARCH ON BSE)
- ANEXO I SOLICITUD DE SERVICIO DE BANDO DE DEFUNCIÓN
- BASELINE BASICS PURPOSE IDENTIFY AND CHARACTERIZE ENVIRONMENTAL ISSUES
- CHAPTER 19—LIFE ON OTHER WORLDS MULTIPLE CHOICE IDENTIFY THE
- PLEASE ALSO REFER TO THE PUBLISHED VERSION OF THIS
- [MULE8295] UPGRADE TO GRIZZLY 2319 CREATED 05FEB15 UPDATED 04JUL17
- JEZIKOVNE TEHNOLOGIJE 20052006 FIDAPLUS HTTPWWWFIDAPLUSNET IZHOD DOMOV ENOVRSTIČNO ISKANJE
- cri Electrical Circuit Code 40826 Item 310 Singleprime Licensed
- NAME PERIOD RECONSTRUCTION PICTURE BOOK OR COMIC STRIP PROJECT
- CAMPEONATO REGIONAL DEL DEPORTE EN EDAD ESCOLAR 20182019 ATLETISMO
- WARRIOR FOOTBALL ELITE CAMP RISING 2017 8TH AND 9TH
- SESION EXTRAORDINARIA DEL DIA 21 DE JUNIO DE 2003
 MUNICIPALIDAD DE CINCO SALTOS RÍO NEGRO ORDENANZA MUNICIPAL Nº
MUNICIPALIDAD DE CINCO SALTOS RÍO NEGRO ORDENANZA MUNICIPAL NºMATLAB EXERCISES (SESSION 1) 1 COMPUTE THE GOLDEN RATIO
 VANISHING DIFFERENCES–A TRAINER’S PERSPECTIVE ON LJUBLJANA ALLAN LOUDEN WAKE
VANISHING DIFFERENCES–A TRAINER’S PERSPECTIVE ON LJUBLJANA ALLAN LOUDEN WAKEWYBRANE WZORY KORESPONDENCJI DYPLOMATYCZNEJ AGRÉMENT GODŁO PAŃSTWOWE NR DZIENNIKA
HELSINGIN TIISTAI JA SUNNUNTAI OARYHMIEN PALAVERIKÄYTÄNNÖISTÄ MUOKANNUT PETRIIKKA 2014
TOWARDS UNDERSTANDING SECURITY EDUCATION MARKUS JAKOBSSON MARKUSJAKOBSSONPARCCOM THIS NOTE
 PROVINCE DU BRABANT WALLON ZONE DE POLICE « LA
PROVINCE DU BRABANT WALLON ZONE DE POLICE « LA P UBLIC SERVICE ANNOUNCEMENT DAM FAILURE INSERT PHOTO HERE
P UBLIC SERVICE ANNOUNCEMENT DAM FAILURE INSERT PHOTO HEREOBRAZLOŽENJE PRIHODA I PRIMITAKA RASHODA I IZDATAKA UZ GODIŠNJI
TTK TOPLULUĞUNDA MALULİYET VE ÖLÜMLE SONUÇLANAN İŞ KAZASI VE
 GÚT ÁLTALÁNOS ISKOLA ÓVODA ÉS BÖLCSŐDE PEDAGÓGIAI PROGRAMJA ÉS
GÚT ÁLTALÁNOS ISKOLA ÓVODA ÉS BÖLCSŐDE PEDAGÓGIAI PROGRAMJA ÉS N OM PRÉNOM EVALUATION 2 J E SAIS
N OM PRÉNOM EVALUATION 2 J E SAIS 38 & JEFREMIENKO MUNICYPALNE USŁUGI DORADCZE DIAGNOZA OBSZARU
38 & JEFREMIENKO MUNICYPALNE USŁUGI DORADCZE DIAGNOZA OBSZARUINSTITUTO ELECTORAL Y DE PARTICIPACIÓN CIUDADANA DE YUCATÁN ACTA
CLAVE 10 DE RANGER AMERICAN 100 PRUEBA DE COMUNICACIÓN
 PRÉNOM COLORIE TON PRÉNOM DANS LE NUAGE DE
PRÉNOM COLORIE TON PRÉNOM DANS LE NUAGE DE REPUBLIKA HRVATSKA BJELOVARSKOBILOGORSKA ŽUPANIJA OPĆINA VELIKI GRDEVAC OPĆINSKO VIJEĆE
REPUBLIKA HRVATSKA BJELOVARSKOBILOGORSKA ŽUPANIJA OPĆINA VELIKI GRDEVAC OPĆINSKO VIJEĆEROASTED BEETROOT PASTA (FROM ABEL + COLE RECIPE BOOK)
DESCRIPCIÓN DE LAS CLAVES UTILIZADAS EN LOS CAMPOS RESALEG
 SESEÑA CALLE DE GUADALAJARA 1 COD 45223 TELÉFONOS 678
SESEÑA CALLE DE GUADALAJARA 1 COD 45223 TELÉFONOS 678
