COMPUTER RECOGNITION OF SPOKEN HINDI SAMUDRAVIJAYA K TATA INSTITUTE
ANNEX B2 PRODUCT ENVIRONMENTAL ATTRIBUTES COMPUTERS AND(6030154) 5 N240(E)(M31)H NATIONAL CERTIFICATE COMPUTERISED FINANCIAL SYSTEMS N4
(IJCSIS) INTERNATIONAL JOURNAL OF COMPUTER SCIENCE AND INFORMATION SECURITY
(SAVE THIS FORM TO YOUR COMPUTER TO BEFORE BEGINNING)
1 SPECIFICATIONS FOR DESKTOP COMPUTERSM90Z PROCESSORS INTEL® CORE™
10 THE STATUTES AND REGULATIONS RELATING TO BS (COMPUTER
Computer Recognition of Spoken Hindi
Computer Recognition of Spoken Hindi
Samudravijaya K
Tata Institute of Fundamental Research, Homi Bhabha Road, Mumbai 400 005
Email: [email protected]
Abstract
A preliminary report of the development of a speaker independent, continuous speech recognition system for Hindi is presented. The system recognises spoken queries in Hindi in the context of railway reservation enquiry task. A spoken sentence is represented as a sequence of 48 context independent acoustic-phonetic units, each modelled by a hidden Markov model. The performance of the system for test as well as training data collected from 10 speakers, both male and female, is reported.
1 Introduction
With the integration of computers and telecommunications, remote access of information stored in a central location or distributed across the world has become much easier. Here, the mode of information access becomes an important issue. The designs of the prevalent human machine interfaces are more suitable for easier interpretation of information by computers than by human beings. The concept of machine being able to interact with people in a mode that is natural as well as convenient for human beings is very appealing. Issuing spoken commands to a machine to get useful work done and to listen to the response is a long held dream. This has motivated research in speech recognition as well as speech synthesis. Considerable progress has been made and a few commercial speech products of varying capabilities are available for use in quite a few languages.
It is desirable that the human machine interaction in voice mode facilitates communication in one’s native language. This is especially important in a multi-lingual country such as India where a large majority of the people will not be comfortable with speaking, reading or listening English-the de facto language of interaction with computer. Thus, there is an urgent need for developing systems that enable human machine interaction in Indian languages. Some of the efforts made in this direction are recognition of isolated Bengali words [1], micro-processor based isolated word recognition system [2], word boundary hypothesization in continuous speech in Hindi [3,4] as well as Telugu [5], recognition of Hindi sentences spoken with pauses between words [6], recognition of Consonant-Vowel(CV) utterances [7]. These systems address various issues of recognising utterances in an Indian language; however, they require either pause between words, or detection of recognition units (for example, CV units), or are speaker-dependent. This paper presents a preliminary report of the development of a speaker independent, continuous speech recognition system for Hindi. The system recognises spoken queries in Hindi in the context of a railway reservation enquiry task. It recognises sentences spoken naturally (without the need for a pause between words), and is speaker independent.
2 Speech Database
Training and testing a speech recognition system needs a collection of utterances appropriate for the task on hand. The generation of a corpus of Hindi sentences and the collection of speech data are described below.
2.1 Sentence corpus
Since the sentences pertain to typical questions asked in a railway enquiry counter, a set of such query in Hindi was generated from a set of sentence templates. These sentence templates were formed in terms of word categories such as train names, city names, classes of tickets etc.The sentence corpus consists of 320 sentences and the size of the vocabulary was 161 words. The sentences in the corpus were so chosen that the corpus contains atleast 3 repetitions of each word in the lexicon. The following are two sentences in the sentence corpus.
kyaa kurla tiruvanantapuram express kaa teis ac two tier sleeper kaa ticket parson ke liye mil_saktaa hei
tiruvanantapuram se jammu_tawi ke liye ac first class kaa kiraayaa kitnaa hogaa
2.2 Data collection
The database consists of 400 sentences. Ten subjects (7 male and 3 female) read 40 sentences each in a natural manner. Speech was simultaneously recording using two microphones. Subjects held a high quality, directional microphone (Shure SM48 low impedance) at a distance about 5-10 cms from their mouth while reading the sentence. Another ordinary microphone (normally supplied with the multimedia PCs) was placed on a desktop mount at about 1 metre from the subject's mouth. As the close-talking microphone was held by hand, sometimes there were some amplitude variations from sentence to sentence for a given speaker. The data collected from the desktop microphone contains the effect of room acoustics and the background noise in the computer room. This data can be used for studying and comparing various speech enhancement techniques for speech recognition. The speech data was sampled at 16kHz and quantized with 16 bits using Sound Blaster Live card. The data was stored in PCM format without any header and organised in speaker-specific directories. Each sentence was stored in a separate file, whose filename indicated the identities of the speaker, microphone, session and the sentence in the database. The speech data collected using the close talking microphone was used in the experiments.
3 Experimental details
3.1 Signal processing
The speech data was blocked into overlapping frames of 25msec duration, the shift between successive frames being 10 frames, and multiplied by Hamming window. Twelve cepstral coefficients were derived from the output of 26 mel filters. The cepstral coefficients were liftered using a raised sine window of length 24. The 12 liftered mel-frequency cepstral coefficients (MFCC) form the feature vector representing a frame of speech.
3.2 Speech model
Hidden Markov model (HMM) [8] was used for representing speech units. Forty eight phone-like acoustic-phonetic units were used to represent Hindi sentences. Only monophone models were used due to paucity of sufficient speech data. The plosives were represented as two units-the first representing the closure, and the second representing the rest of the stop consonant. While distinction was maintained between the releases of aspirated and unaspirated plosives, no such distinction was retained between their closures. In addition to the Hindi phonemes, a few commonly occurring English vowels such as /ae/ were included in the list of units.
The HTK software by Entropic software was used in this experiment. A simple left-to-right HMM topology containing 3 emitting states was used to model a unit as shown in the Figure 1. Each emitting state was associated with a single multivariate Gaussian with diagonal covariance. Silence was represented as a separate unit, obviating the need for silence detection in the signal processing state. A short pause model was used to capture brief pauses, if any, between words in an utterance.

Figure 1. The topology of the HMM. It has 3 emitting states.
Out of 40 sentences spoken by each speaker, the first 20 sentences from every speaker (a total of 200 sentences) were used for training the system using Viterbi alignment method. The training used a label file and a phonetic dictionary. The label file contains word level transcriptions of each sentence and the phonetic dictionary has the transcription of each word in the vocabulary in terms of the 48 units. A finite state grammar in Backus Naur Form was used to represent the grammar of the specific task domain during testing. The performance of the system with training and test data is discussed in the next section.
4 Results and discussion
The performance of the system was measured by computing the recognition accuracy at the sentence as well as the word level. The Hvite tool of HTK was used to hypothesise the best sentence within the task grammar matching with the sequence of feature vectors. The Hresults tool of HTK was used to compute the accuracy by comparing the hypothesised sentences and the actual transcription. The columns in the Table 1 show the percent accuracy of recognition as well as the number of words and sentences in the test suite. The first row refers to the case when the system is fed with the speech data with which the system was trained. The second row pertains to the test data, i.e., the speech data that the system has not “seen” during training. Here, the word accuracy is defined as
100 * No. of correctly recognised words
word accuracy = ---------------------------------------
Total no. of words in the test suite
The sentence accuracy is defined as 100 times the ratio of the number of sentences in which all words are correctly recognised to the total number of sentences in the test suite. From the table, it can be seen that the word accuracies of the system for both training data and test data are 93%. Also, the majority of the sentences are recognised with all the words correctly hypothesised in both cases.
|
type of data |
number of |
accuracy (%) |
||
|
|
sentences |
words |
sentences |
words |
|
training |
198 |
1878 |
56 |
93 |
|
test |
156 |
1511 |
53 |
93 |
Table 1. Performance of the Hindi speech recognition system for training and test data.
The performance of the system can be improved by incorporating several enhancements. The current system employs MFCC to represent speech frames. This feature vector does not take into account the systematic temporal variation of spectrum. The accuracy of the recognition system can be improved by using dynamic features such as delta-MFCC, which capture, in a simple way, the spectral dynamics. Better accuracy can be obtained by enhancing the lexical module as well. Multiple pronunciations (in terms of the acoustic-phonetic units) can be allowed for a given word in the lexicon. This will take care of different pronunciations of a given word by different persons. At the model level, gender identification technique can be used and the test feature vector sequence can be matched with a gender dependent HMM. Initialisation of emission probability densities of HMM states using a segmented and labelled speech database [9] should lead to better models with the limited training data. In addition, context dependent acoustic-phonetic units such as triphones can be used. However, this increases the number of parameters to be estimated, which in turn demands a larger speech corpus for training. Meanwhile, speech data is being collected on a regular basis and the aforementioned improvements will be incorporated into the system.
The recognition experiments have been carried out under certain constraints. The results reported for the test data belong to the “training” speakers (the first 20 sentences spoken by every “test speaker” were used for training the system). Also, both training and test data were recorded in a single recording session using the same microphone. It would be interesting to investigate the performance of the system for data collected from (a) training speakers in a new recording session, (b) training speakers using a different microphone and (c) new test speakers. These experiments are in progress.
5 Conclusions
There is an urgent need for development of a convenient, multi-modal human computer interface that enables a wider population of the country to reap the benefits of computers. Here, the role of speech interface cannot be overemphasised as it is the most natural and convenient mode of communication among human beings. Satisfactory speech recognition accuracy can be obtained using sophisticated statistical model such as HMM that adequately characterises the temporal aspect of the speech signal in addition to its spectral properties. Utilisation of more training data together with detailed modelling of speech signal can raise the system performance to a level adequate for actual deployment in appropriate task domains.
Acknowledgments
The assistance of Ms. Pallavi Chaturvedi in this work is acknowledged. We thank Prof. R.K.Shyamasundar for his encouragement. This work has been supported by the E-commerce project sponsored by the Ministry of Information Technology, Government of India.
References
Somnath Majumder and A.K.Dutta, ``Automatic recognition of isolated Bengali words’’, Proc. Int. Workshop titled ``Speech technology for man-machine interaction’’, Eds. PVS Rao
and BB Kalia, Tata McGraw Hill, 1990, pp. 283-288.
[2] Abdul Mobin, S.S.Agrawal, Anil Kumar and K.D.Pavate, “A voice input-output system for
isolated words”, Proc. Int. Workshop titled ``Speech technology for man-machine interaction’’, Eds. PVS Rao and BB Kalia, Tata McGraw Hill, 1990, pp. 283-288.
[3] G. V. Ramana Rao and B. Yegnanarayana, Word boundary hypothesization in Hindi speech,
Computer Speech and Language, vol. 5, no. 4, pp.379-392, Dec. 1991.
[4] S. Rajendran and B. Yegnanarayana, ``Word boundary hypothesization for continuous speech
in Hindi based on F0 patterns’’, Speech Communication, 18, pp.21-46, Jan. 1996.
[5] B.V.L.Narasimha Prasad and C.M.Balakrishna, ``Word Boundary Hypothesization in Telugu
Speech’’, in ‘Information Technology Applications in Language, Script \& Speech’, Eds.
S.S.Agrawal and Subas Pani, BPB Publications, New Delhi, 1994, pp.135-141.
[6] K.Samudravijaya, R.Ahuja, N.Bondale, T.Jose, S.Krishnan, P.Poddar, P.V.S.Rao and
R.Raveendran, ``A feature-based hierarchical speech recognition system for Hindi’’,
Sadhana, 23, part 4, 1998, pp. 313-340.
[7] C.Chandra Sekhar and J.Y.Siva Rama Krishna Rao, “Reordering network as postprocessor
in modular approach based neural network architecture for recognition of consonant-
vowel(CV) utterances’’, Proc. Of SPCOM-99, Eds A.Makur and T.V.Srinivas, Viva Books
Pvt Ltd, New Delhi, 1999, pp. 109-114.
[8] L.R.Rabiner, “A Tutorial on Hidden Markov Models and Selected Applications in Speech
Recognition”, Proc. IEEE, 77 (2), pp. 257-286, February 1989.
[9] Samudravijaya K, P.V.S.Rao and S.S.Agrawal, “Hindi speech database”, in Proc. Int. Conf.
Spoken Language Processing, ICSLP00, October, Beijing.
1504 WIS JI‑CRIMINAL 1504 1504 COMPUTER CRIME — §
16 MEMORY COMPUTER SCIENCE 240 LABORATORY 7 IN LAB
216 MALVERN HOT SPRING COUNTY LIBRARY COMPUTERINTERNET USE
Tags: computer recognition, speech, computer, spoken, institute, computer, hindi, recognition, samudravijaya
- PERJANJIAN PERKHIDMATAN KAWALAN KESELAMATAN PERJANJIAN INI DIBUAT PADA ………
- PRAVĚK PERIODIZACE PRAVĚKU 1 A) DOBA KAMENNÁ PALEOLIT
- ANEXO 3 AGREED STATEMENT FROM THE GLOBE G8+5 LEGISLATORS’
- DILUTIONS WORKSHEET 1) IF I HAVE 340 ML OF
- SZKOŁA POLICEALNA CENTRUM NAUKI I BIZNESU „ŻAK” PLAN ZAJĘĆ
- VĀRKAVAS NOVADA DOME VECVĀRKAVA SKOLAS 5 TĀLRUNIS 653965365329632 LV5335
- GŁOSOWANIE KORESPONDENCYJNE GŁOSOWAĆ KORESPONDENCYJNIE MOGĄ WYBORCY POSIADAJĄCY ORZECZENIE O
- TABLEAU DE CORRESPONDANCE ENTRE HORAIRE ANNUEL JOURS FÉRIÉS COMPRIS
- THIS ACTIVITY IS ABOUT CONVERTING BETWEEN FRACTIONS DECIMALS AND
- DELEGATED COMMITTEES (FORMERLY KNOWN AS SPECIAL COMMITTEES) ESTABLISHED BY
- TOWARDS THE COMPLETION OF FRAMEWORK IMPLEMENTATION IN THE UNIVERSITIES
- O P ET CACHET DATEUR OFFICE NATIONAL DE L’EMPLOI
- SENACKA KOMISJA DS DYDAKTYKI I WYCHOWANIA 1 PRZEWODNICZĄCY DR
- DOCUMENTO Nº 5 CENTRO EDUCATIVO RECOGIDA DE DATOS SOCIODEMOGRÁFICOS
- BIAŁYSTOK DNIA 13032019R KOMUNIKAT Z ETAPU OKRĘGOWEGO OGÓLNOPOLSKIEJ OLIMPIADY
- ASIGNATURA ASESORAMIENTO VOCACIONAL EN LA ENSEÑANZA PRIMARIA SECUNDARIA AÑO
- COMPANY PROFILES OF SVERDLOVSK REGION DELEGATION TO HA NOI
- MULTICLUSTER INITIAL RAPID ASSESSMENT – MIRA FORMULARIO MÓDULO DE
- 33 33 FRAGMENTO DE LIBRO “ASPECTOS PROCESALES CIVILES
- ART LOAN APPLICATION FORM PLEASE READ THE FOLLOWING GUIDELINES
- H OJA DE PREINSCRIPCIÓN ACTIVIDADES DEPORTIVAS SECO ADULTOS Y
- CROATIAN PANEUROPEAN UNION SPLIT SECOND PANEUROPEAN SHIPPING CONFERENCE SPLIT
- ÇEVRE VE ŞEHİRCİLİK BAKANLIĞI COĞRAFI BILGI SISTEMLERI GENEL MÜDÜRLÜĞÜ
- REJESTR DZIAŁALNOŚCI REGULOWANEJ W ZAKRESIE ODBIORU ODPADÓW KOMUNALNYCH NA
- INGRIJITOAREA (INFIRMIERA) ŞI LOCUL EI DE MUNCĂ INGRIJITOAREA ASIGURĂ
- APRENDIZAJE MOTOR LAS HABILIDADES MOTRICES BÁSICAS COORDINACIÓN Y EQUILIBRIO
- LAW OF THE KYRGYZ REPUBLIC ON LEGAL PROTECTION OF
- CONSEJO DE ACCESIBILIDAD IRISGARRITASUNERAKO KONTSEILUA C Nº ACTA
- SANTA GERTRUDIS ORIGEN ESTA RAZA FUE DESARROLLADA EN KING
- APPLYING THE CONCEPTS CHAPTER 4 FOR EXERCISES THAT HAVE
LIST OF SWIM REFERENCES IN THE PARTNER COUNTRIES COUNTRY
 N OTA DE PRENSA PARA SU PUBLICACIÓN INMEDIATA ARVATO
N OTA DE PRENSA PARA SU PUBLICACIÓN INMEDIATA ARVATOSzczegółowe Kryteria Oceniania Klasa iv „słuchamy Boga”
 HOW TO CREATE NOTE CARDS AS YOU CONSULT DIFFERENT
HOW TO CREATE NOTE CARDS AS YOU CONSULT DIFFERENT APRECIAD COMPAÑER NOS PONEMOS EN CONTACTO PARA RECORDARTE QUE
APRECIAD COMPAÑER NOS PONEMOS EN CONTACTO PARA RECORDARTE QUEU ESTHER MESSINGER BRISTOL CATHEDRAL SCHOOL 2017 NFINISHED GCSE
 CCPS INTERNATIONAL CONFERENCE AND WORKSHOP OCTOBER 25 2001 TORONTO
CCPS INTERNATIONAL CONFERENCE AND WORKSHOP OCTOBER 25 2001 TORONTOUCHWAŁA NR XXIII13305 RADY GMINY ŁUBNIANY Z DNIA 26
ENRIQUE FLORESCANO DE LA MEMORIA DEL PODER A LA
KONVENCIJA O ELIMINISANJU SVIH OBLIKA DISKRIMINACIJE ŽENA 1 DRŽAVE
LR 3 MAGGIO 2002 N 16 DISCIPLINA GENERALE DEGLI
COMPOSICIÓN DE LOS ENVASES LOS ENVASES DE VIDRIO SON
ZAKOŃCZENIE PROWADZENIA DZIAŁALNOŚCI GOSPODARCZEJ ZAKOŃCZENIE PROWADZENIA DZIAŁALNOŚCI GOSPODARCZEJ WIĄŻE
 CAMPO%20ELECTRICO
CAMPO%20ELECTRICOOIRLEGISLATINA REGLAMENTO INTERIOR DE LA ASAMBLEA LEGISLATIVA DE EL
 WORKING WITH CHILDREN POLICY PREAMBLE THE WORKING WITH CHILDREN
WORKING WITH CHILDREN POLICY PREAMBLE THE WORKING WITH CHILDREN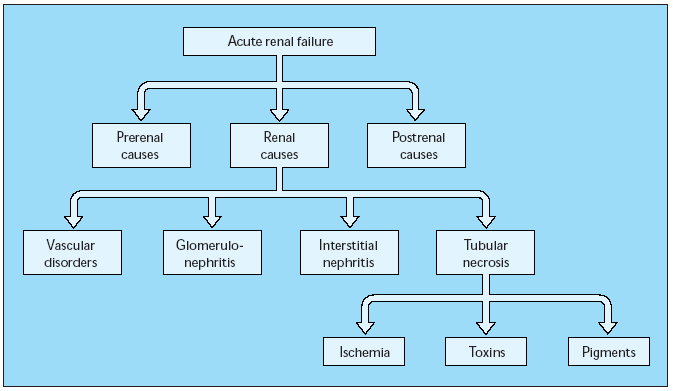 ACUTE RENAL FAILURE ADAPTED FROM UPTODATE “CLINICAL PRESENTATION EVALUATION
ACUTE RENAL FAILURE ADAPTED FROM UPTODATE “CLINICAL PRESENTATION EVALUATION CITY OF BETHLEHEM INTERDEPARTMENTAL CORRESPONDENCE SUBJECT REQUEST FOR APPROVAL
CITY OF BETHLEHEM INTERDEPARTMENTAL CORRESPONDENCE SUBJECT REQUEST FOR APPROVAL STSGAC10C32004 PAGE 0 UNSCETDG26INF7 COMMITTEE OF EXPERTS ON
STSGAC10C32004 PAGE 0 UNSCETDG26INF7 COMMITTEE OF EXPERTS ONZWIĄZEK HARCERSTWA POLSKIEGO HUFIEC „RÓJ PROMIENISTYCH” IM TADEUSZA ZAWADZKIEGO
