DISEÑO Y ANÁLISIS DE ALGORITMOS 1 SEM 2007 DR
Análisis y Diseño de Sistemas ii lic Eliza ArizacaDiseño Curricular Indice Lengua Fundamentación 5 Finalidades Educativas 9
Escuela Técnica Superior de Ingeniería del Diseño Asignatura Fisicoquimica
Facultad de Educación [diseño Organizacional ] Uncp
Normas Técnicas Complementarias Para Diseño y Construcción de Cimentaciones
Skip lists
Diseño y Análisis de Algoritmos 1 Sem. 2007 Dr. Eric Jeltsch F.
Skip lists
Se sabe que una de las maneras más simples de implementar el TDA diccionario es utilizando una lista enlazada, pero también se sabe que el tiempo de búsqueda promedio es O(n) cuando el diccionario posee n elementos. Es decir, el costo de una búsqueda en el caso peor es lineal en el número de nodos. Por otra parte, claramente es imposible realizar una búsqueda binaria, ya sea por bisección o por trisección, sobre una lista enlazada ordenada; porque no existe manera de calcular desde las direcciones de dos elementos i y j, con valores xi y xj para X, la dirección de un elemento con un valor de X intermedio entre xi y xj . Esto se debe a que las celdas que contienen elementos de la lista pueden provenir arbitrariamente desde cualquier parte de la memoria.

De hecho, ésa fue la razón que nos llevó a acotar el uso de dicho tipo de listas; a pesar de que las modificaciones estructurales sobre ellas eran poco costosas (de orden (1)).
Es así como la localización es secuencial y, por lo tanto, el peor caso de localización exitosa sería de N celdas consultadas (el peor caso de localización sería de N +1 celdas consultadas). La figura siguiente muestra un ejemplo de lista enlazada simple con “head”, donde los elementos están ordenados ascendentemente:
![]()
Por otro lado sabemos, la existencia de las Skip List, debido a William Pugh:

De manera que, es posible modificar la estructura de datos de la lista y así mejorar el tiempo de búsqueda promedio. La siguiente figura muestra una lista enlazada en donde a cada nodo par se le agrega una referencia al nodo ubicado dos posiciones más adelante en la lista. Modificando ligeramente el algoritmo de búsqueda, a lo más techo(n/2)+1 nodos son examinados en el peor caso. Tal como se puede apreciar, para n=10,

Esta idea se puede extender agregando una referencia cada cuatro nodos. En este caso, a lo más techo(n/4)+2 nodos son examinados:

El caso límite para este argumento se muestra en la siguiente figura. Cada 2i nodo posee una referencia al nodo 2i posiciones más adelante en la lista. El número total de punteros se ha duplicado (con respecto a la lista enlazada inicial). Ahora el tiempo de una búsqueda está acotado superiormente por techo(log2 n), porque la búsqueda consiste en avanzar al siguiente nodo (por el puntero alto) o bajar al nivel siguiente de punteros y seguir avanzando…En esencia, se trata de una búsqueda binaria. Notar que el número total de referencias solo ha sido doblado, pero ahora a lo más techo(log2 n) nodos son examinados durante la búsqueda. Note que la búsqueda en esta estructura de datos es básicamente una búsqueda binaria, por lo que el tiempo de búsqueda en el peor caso es O(log n).

El problema que tiene esta estructura de datos es que es demasiado rígida para permitir inserciones de manera eficiente. Por lo tanto, es necesario relajar levemente las condiciones descritas anteriormente para permitir inserciones eficientes.
Se define un nodo de nivel k como aquel nodo que posee k referencias. Se observa de la figura anterior que, aproximadamente, la mitad de los nodos son de nivel 1, que un cuarto de los nodos son de nivel 2, etc. En general, aproximadamente n/2i nodos son de nivel i. Cada vez que se inserta un nodo, se elige el nivel que tendrá aleatoriamente en concordancia con la distribución de probabilidad descrita. Con esta idea logramos mejorar los esfuerzos de localización, pero a costa de aumentar la cantidad de punteros; es decir, de aumentar el espacio utilizado para la representación de la estructura. En general, si tenemos una lista con n elementos, tendremos a lo sumo log n punteros por celda. En la mayoría de las celdas no se necesitarían tantos punteros, porque la mitad de los elementos necesitan sólo un único campo de puntero, y de los restantes elementos sólo la mitad necesitaría un puntero adicional, y así sucesivamente. De manera que, hay n/2 celdas con sólo 1 puntero, n/4 celdas con 2 punteros, n/8 celdas con 3 punteros; y en general, n/2ii celdas con i punteros.
La skip list en sí misma se puede implementar como una estructura de registro de dos campos: Cabecera, la cual sería una celda ficticia para comenzar las listas, y Nivel, el cual sería un entero que daría el nivel más grande de cualquier celda presente actualmente en la lista. Una celda tendría, además de los campos para almacenar X e Y, una tabla de apuntadores a las siguientes celdas de acuerdo a las listas en las que dicha celda participa. El tamaño de esta tabla dependería del nivel de la celda, pero dicho número no necesitaría ser almacenado en la celda. Inicialmente el Nivel de una skip list sería 0 y todos los apuntadores apuntarían a la celda ficticia final cuyo valor almacenado en el campo X sería, como ya habíamos expresado, el valor considerado “” para cualquier valor posible de X. La siguiente figura muestra la situación inicial de una skip list con máximo nivel = 3:
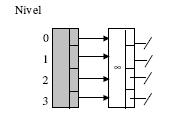
Por ejemplo, se puede lanzar una moneda al aire, y mientras salga cara se aumenta el nivel del nodo a insertar en 1 (partiendo desde 1). Esta estructura de datos es denominada skip list. La siguiente figura muestra un ejemplo de una skip list:

Búsqueda en una skip list
Suponga que el elemento a buscar es X. Se comienza con la referencia superior de la cabecera. Se realiza un recorrido a través de este nivel (pasos horizontales) hasta que el siguiente nodo sea mayor que X o sea null. Cuando esto ocurra, se continúa con la búsqueda pero un nivel más abajo (paso vertical). Cuando no se pueda bajar de nivel, esto es, ya se está en el nivel inferior, entonces se realiza una comparación final para saber si el elemento X está en la lista o no. El algoritmo sería algo así:
- Comenzando con los punteros del mayor nivel, seguirlos hasta que se encuentre un
elemento con valor de X mayor o igual que el x buscado.
- Si en dicha celda el valor de X encontrado es igual al x buscado, paramos y la búsqueda tuvo éxito; si en otro caso es mayor que el x buscado, volvemos hacia atrás un puntero y continuamos siguiendo los punteros del siguiente nivel más bajo.
- Si un puntero de nivel 0 guía a un elemento con valor de X mayor que el x buscado, paramos y la búsqueda fracasó.
Ejemplo:
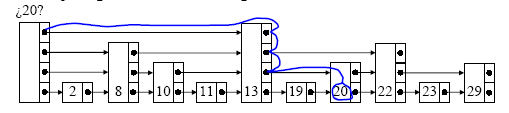
Se empieza con el puntero más alto de la “head”.
Se continúa por ese nivel hasta encontrar un nodo con clave mayor que la buscada (o NIL), entonces se desciende un nivel y se continúa de igual forma.
Cuando el avance se detiene en el nivel 1, se está frente al nodo con la clave buscada o tal clave no existe en la lista.
Inserción en una skip list
Se procede como en la búsqueda, manteniendo una marca en los nodos donde se realizaron pasos verticales, hasta llegar al nivel inferior. El nuevo elemento se inserta en la posición en donde debiera haberse encontrado, se calcula aleatoriamente su nivel y se actualizan las referencias de los nodos marcados dependiendo del nivel del nuevo nodo de la lista.
Para insertar un elemento en una skip list necesitaríamos primero tener una rutina que genere los números aleatorios apropiados del nivel. En general, se puede contar con una función Random() disponible en la mayoría de los lenguajes de programación, la cual devuelve un número aleatorio k en el rango 0 k < 1 con distribución uniforme.
Ejemplo:
Primero: para insertar un nuevo elemento hay que decidir de qué nivel debe ser.
• En una lista de las del “caso límite” la mitad de los nodos son de nivel 1, una cuarta parte de nivel 2 y, en general, 1/2i nodos son de nivel i.
• Se elige el nivel de un nuevo nodo de acuerdo con esas probabilidades: se tira una moneda al aire hasta que salga cara, y se elige el número total de lanzamientos realizados como nivel del nodo. Distribución geométrica de parámetro p = 1/2. (En realidad se puede plantear con un parámetro arbitrario, p, y luego seleccionar qué valor de p es más adecuado).
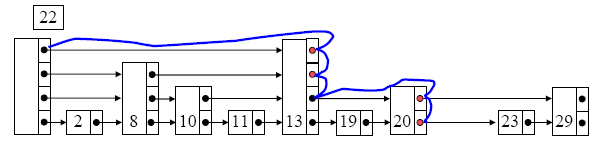
Segundo: hay que saber dónde insertar.
• Se hace igual que en la búsqueda, guardando traza de los nodos en los que se desciende de nivel. Se determina aleatoriamente el nivel del nuevo nodo y se inserta, enlazando los punteros convenientemente.

En la dirección dada más abajo, encontraran una buena simulación de la inserción de una clave, en este caso 11, aunque la probabilidad no aparece mencionada, sino que se genera aleatoriamente.
http://eupt2.unizar.es/asignaturas/itig/estructuras_de_datos/temario/Skip-Lists.html
Borrado en una skip list
La eliminación en una skip list es bastante similar a la inserción, primero se debe localizar al elemento manteniendo, como ya habíamos mencionado máximo nivel +1 apuntadores, donde punti mantendrá un puntero a la celda de más a la derecha de nivel i o superior que es anterior a la posición de la celda que contiene el x buscado. Pero, para poder utilizar la misma rutina de Localización para todas las otras rutinas, es necesario que la localización exitosa llegue indefectiblemente hasta el nivel 0 y no se detenga en niveles mayores para así poder registrar, en los punteros auxiliares, las direcciones de todas las celdas que son factibles de modificación luego de la baja. Por lo tanto, luego de que la localización tenga éxito y conociendo las direcciones de las celdas anteriores a la celda que se quiere dar de baja, en las listas de cada uno de los niveles, se procede a actualizar sólo los apuntadores de los niveles hasta el nivel de la celda a dar de baja.
Por ejemplo, si se desea eliminar el elemento 10 de la lista anterior, la localización exitosa nos brindaría la siguiente información útil:

y luego de la modificación estructural la skip list quedaría como:

Los apuntadores que aparecen remarcados son los únicos que se modifican para reflejar la baja de la celda de nivel 1 conteniendo el valor 10. Por ser la celda de nivel 1 sólo se modifican los apuntadores hasta dicho nivel, en este caso para reflejar la baja en las listas de nivel 0 y de nivel 1.
Tags: algoritmos 1, análisis, algoritmos, diseño
- LA VALISE TYPE DOCUMENTS ESSENTIELS PASSEPORT ET CARNET
- HONORABLE CÁMARA DE DIPUTADOS PROVINCIA DE CORRIENTES EXPTE 14878
- MIREIA PÉREZ TORRENT SARA TORRAS MARTÍNEZ 3R EDUCACIÓ INFANTIL
- ACCESO A LA UNIVERSIDAD PARA MAYORES DE 25 40
- SITUACIÓN DE LOS DERECHOS DE LOS PUEBLOS INDÍGENAS EN
- FACULTY OF HEALTH AND SOCIAL CARE EQUAL OPPORTUNITIES INFORMATION
- MYKOLO ROMERIO UNIVERSITETO STRATEGINIO VALDYMO IR POLITIKOS FAKULTETAS PATVIRTINTA
- Ðïࡱáþÿ ¥áq ¿bjbjt+t+ 0aaâgÿÿÿÿÿÿ]x92x92x92x92nnnbbbbb Nbt¶x8ex8ex8ex8e¶ggg9ô ¶ngë|gggx8bx92x92x8e¶x8ex8bx8bx8bgx92x86x8e(n¶9bbx92x92x92x92g9x8b®x8b96n9¶x82 Àã¨îdæbbc(9goulds Turkeys Making
- TABELA GRUBOŚCI PRZYROSTU LODU WARUNKI BEZWIETRZNE POKRYWA ŚNIEŻNA NIE
- FAS PERFORMANCE AND BUDGET INTEGRATION PLAN 2003 2006
- AUTORIZACIÓN DE DERECHOS DE IMAGEN Y TRATAMIENTO DE DATOS
- AHRC2747 UNITED NATIONS AHRC2747 GENERAL ASSEMBLY DISTR GENERAL 30
- COMMON GROUND A CROSSCULTURAL SELFDIRECTED LEARNER’S INTERNET GUIDE INDIVIDUAL
- 10 THINGS THAT HAVEN’T CHANGED IN THE PAST YEAR
- EECE324 REV1ADD82REV2 EECETRANS505} REGULATION NO 83 PAGE 5 ANNEX
- IMIĘ I NAZWISKO DOKTORANTA NAZWA PRACOWNI IMIĘ I NAZWISKO
- NOMBRE ESPAÑOL III HONORS VERB CHART PRESENT AR YO
- STRAND II CHEMICAL STRUCTURES AND PROPERTIES SYNTHETIC POLYMERS LABORATORY
- OPTYMALIZACJA ZAPYTAŃ SQL ANDRZEJ PTASZNIK WARSZAWSKA WYŻSZA SZKOŁA INFORMATYKI
- CONFIGURACION DE CUENTAS INSTITUCIONALES ASOCIADAS A CUENTAS PERSONALES NOTA
- FORSKNINGSAVDELINGEN TIL ADRESSATER PÅ VEDLAGT LISTE RAPPORTERING TIL NORGES
- RE 51 REPRO A ZVUKOVKA SB LIVE 51! MA
- 22 RÚBRICA PER A LA COAVALUACIÓ DE COM HEM
- TIMBRE DA INSTITUIÇÃO RELAÇÃO DOS FUNCIONÁRIOS DO SERVIÇO DE
- ACERCA DEL ARTÍCULO DE GALLART MARÍA ANTONIA Y JACINTO
- POLSK OG ENGELSK ARBEIDSAVTALE FOR KORTVARIGE FORHOLD WORKTIME AGREEMENT
- E L DIA DE LOS MUERTOS INTRODUCCIÓN ¿SABES QUÉ
- S ISTEMA INSTITUCIONAL DE GESTIÓN DE LA CALIDAD ANEXO
- Edibon Edicióned0117 Fechajulio2017 Peif Equipo de Estudio del Índice
- IS THE SCOTTISH PREMIER LEAGUE LESS COMPETITIVE THAN ITS
 UNIDAD DE COORDINACION DE PRÉSTAMOS SECTORIALES – UCPS DIRECCIÓN
UNIDAD DE COORDINACION DE PRÉSTAMOS SECTORIALES – UCPS DIRECCIÓNTERRIBLE THINGS 1 WHY DO YOU THINK THE AUTHOR
NAME NAME HOLOCAUST WEB QUEST ASSIGNMENT YOU
 SECTION 2 MAKING IT MATTER INTRODUCTION 21 KEY GLOBAL
SECTION 2 MAKING IT MATTER INTRODUCTION 21 KEY GLOBALLAMPIRAN III PERATURAN MENTERI NEGARA LINGKUNGAN HIDUP NOMOR
TEHNISKĀ SPECIFIKĀCIJA NR PK VISPĀRĪGA INFORMĀCIJA 1 AUTOMOBIĻU SKAITS
 HBD INTERNATIONAL CHAT AAV MONTEREY CA 2002 CALCIUM
HBD INTERNATIONAL CHAT AAV MONTEREY CA 2002 CALCIUM DIRECCIÓ DE SERVEIS A LES PERSONES I AL TERRITORI–
DIRECCIÓ DE SERVEIS A LES PERSONES I AL TERRITORI–PLAYER DECLARATION FAMILY NAME(S) FIRST NAME(S) DATE OF BIRTH
 A CONTINUACIÓN LLENA EN EL RECUADRO CORRESPONDIENTE UTILIZANDO SÓLO
A CONTINUACIÓN LLENA EN EL RECUADRO CORRESPONDIENTE UTILIZANDO SÓLONZQA REGISTERED UNIT STANDARD 20553 VERSION 4 PAGE 4
 CONTROLANDO HASTA 8 SERVOMOTORES CON LA INTERFAZ PARA PUERTO
CONTROLANDO HASTA 8 SERVOMOTORES CON LA INTERFAZ PARA PUERTOH 09 CRITERIA FROM CADAVER TRANSPLANTATION CLINIC
 ES TIEMPO DE CAMBIAR TRABAJAMOS COMO DOS LOCOMOTORAS A
ES TIEMPO DE CAMBIAR TRABAJAMOS COMO DOS LOCOMOTORAS A REPASO PARTE 4ª TEMA 10 (NUEVOS DESDE EL 630)
REPASO PARTE 4ª TEMA 10 (NUEVOS DESDE EL 630) INFORMATIKA HARDWARE A SOFTWARE IT OBECNÝ POJEM PŘEDSTAVUJÍCÍ
INFORMATIKA HARDWARE A SOFTWARE IT OBECNÝ POJEM PŘEDSTAVUJÍCÍHENDRIX EDUCATION DEPARTMENT LESSON LINES FOR READING WRITING AND
TÄVLINGSREGLEMENTET FÖR SMÅLANDS SF (SMSF) KAP 1 ALLMÄNNA BESTÄMMELSER
 BASES VI PREMIOS AL VOLUNTARIADO UNIVERSITARIO FUNDACIÓN MUTUA MADRILEÑA
BASES VI PREMIOS AL VOLUNTARIADO UNIVERSITARIO FUNDACIÓN MUTUA MADRILEÑA FOREIGN TRADE ASSOCIATION FTA POSITION REGARDING THE
FOREIGN TRADE ASSOCIATION FTA POSITION REGARDING THE
