MEMORYBASED INDEXING REQUIRES NO TEMPORARY FILES MEMORY NEEDED A
MEMORYBASED INDEXING REQUIRES NO TEMPORARY FILES MEMORY NEEDED A
Sort-based Inversion
Memory-Based Indexing
Requires no temporary files.
Memory needed:
A hashtable (in memory), approx. 3 entries per unique term in collection.
This hashtable has a linked list of all doc_id, tf entries for each term
Essentially: dict and post are both held in memory prior to output
Creates Hash dictionary file.
One-Pass-Algorithm
Goal: create a global hash table of all unique words. For each entry in the hash table, add a linked list storing the postings for that word. Once complete, there is an inverted index in the memory data structure. Just write the hash table to disk in the dict file, and the postings in the post file.
Algorithm
Init the global hash table
For each input document,
// Process all tokens in the document
Init the document hash table, total_freq (i.e., number of terms in the document)
For all terms in the document
If term is not in document hashtable
Add it with tf = 1
Else
Increment the tf for that term
Increment total_freq
For all entries in the document hash table
Add a posting to the global hash table entry for the term containing
doc_id, tf OR rtf = tf/total_freq
// Write the global hashtable to disk as dict and post files
Init start to 0
For each entry in the global hash table
Calculate idf for the term
Write term, start, numDocs to the dict file
For each posting
Write doc_id, tf OR rtf*idf to the postings file
Output:
Dict file (hashtable of fixed length entries)
term numdocs start
quickly 1 0
cat 1 1
blank -1 -1
dog 2 2
blank -1 -1
doctor 1 4
blank -1 -1
duck 1 5
ate 4 6
blank -1 -1
dry 1 10
Post file (Sequential file of fixed length entries)
doc_id tf OR rtf OR wt
0 1
3 1
0 1
1 1
2 2
2 1
0 1
1 2
2 1
3 1
2 1
Pros:
Hashtable for dictionary, therefore fast query processing.
Cons:
Need to be able to store essentially entire document collection in main (not virtual) memory.
This inverts 5 GB in 6 hours using 4 GB memory 0 GB for temporary files.
Multiway Merging – multiple file variation
Requires
1 set of temporary files, one per input document.
A hashtable (in memory), 2-3 entries per unique term in collection.
Essentially: dict is in memory prior to output; postings are always on disk
One merge buffer (one entry per document in the collection).
Creates Hash dictionary file.
Pass I
Goal: create multiple output files, one per input file.
Each record contatins term (or term_id), doci_id (optional) and tf (or relative tf)
Simultaneously, build a global hash table of all unique words.
Algorithm
Init the global hash table
For each input document
Init the document hash table, total_freq (the number of terms in the document)
For all terms in the document
If term not in the document hash table
Add it with a tf = 1
Else
Increment tf for that term
Increment total_freq
For all terms in the document hash table
If term not in global hash table
Add it with numdocs = 1
Give it the next term_id
Else
Increment numdocs
Sort all hashtable entries by term
Open a new temporary file
Write term, doc_id, tf OR rtf = tf/total_freq to temporary file
Close temporary file
After Pass I
0.out term term_id numdocs start
ate 0 1 quickly 3 1 -1
dog 0 1 cat 7 1 -1
quickly 0 1 blank -1 -1 -1
dog 1 2 -1
blank -1 -1 -1
doctor 4 1 -1
1.out blank -1 -1 -1
ate 1 2 duck 6 1 -1
dog 1 1 ate 2 4 -1
blank -1 -1 -1
2.out dry 5 1 -1
ate 2 1
doctor 2 2
dry 2 1
duck 2 1
3.out
ate 3 1
cat 3 1
Pass II
Goal: Merge the output files, calculate idf, write final dict and post files identical to Memory-Based Indexing output (except postings in post file are in alphabetical order)
Create a buffer array with one entry per document (each entry stores term, tf; doc_id is implicit by buffer index).
For all documents
Open file
Load first line into buffer[i]
Until all postings are written
Find alphabetically first token in buffer
Look up term in global hashtable
Update “start” field for the token
Calculate idf for term I from numdocs
Loop over buffer
If (buffer[i] == token)
Write postings record for token (i.e., doc_id, tf OR rtf*idf)
Reload buffer with next record from the file
Numrecords++
Write global hashtable to disk as the dict file
Improvements
Eliminate doc_id from temporary files
If can merge all documents at once, doc_id is implicitly indicated by filename.
Compress temporary file size
Store term_id in hashtable
Use term_id instead of term in temporary files
If cannot have all documents open at a time (usually a limit of several thousand), then can do multiple passes.
Now we do need to store doc_id
e.g., merge 1.out and 2.out -> 1-2.out
merge 3.out and 4.out -> 3-4.out
merge 1-2.out and 3-4.out -> posting file
Pros:
Hashtable for dictionary, therefore fast query processing.
Cons:
Needs 1 set of temporary files, one array entry in MergeArray per document; space for global hashtable (one entry per unique word * 3)
This inverts 5 GB in 11 hours using 40 MB memory and 0.5 GB of for temporary files.
Sort-based Inversion
Requires
2 temporary files, 1 unsorted (from Pass 1); 1 sorted (from Pass 2).
ability to hold all postings for a given term in memory
Unix needs to be able to store and sort the single file of all postings created by Pass I
Creates Sorted dictionary file.
Pass I: Goal: create large temporary file, one entry per term per document, in random
order within document.
Requires a memory data structure (hashtable) per document to count frequency per term in that document.
Algorithm:
Loop over all documents
Init document_hashtable
Loop over all tokens in document
Create valid term
If keep(term)
Increment count of terms in the document
Insert term into document_hashtable
If new, set tf to 0
Else, increment tf
Loop over all terms in the hashtable
If normalizing
rtf = tf /num_terms_in_document
Write (term, doci_id, tf or rtf) to temporary file
Output:
Temporary File 1 with terms grouped by document;
random order within each document):
Term Doc_id tf
quickly 0 1
dog 0 1
ate 0 1
dog 1 1
ate 1 2
dry 2 2
doctor 2 1
ate 2 1
duck 2 1
ate 3 1
cat 3 1
Pass II: Goal: group all postings for the same term together.
Sort the output file by using a Unix sort tool (which is implemented using mergesort) with term_id (or term) as the primary key. Note that if the sort is stable, doc_id is a secondary key “for free.”
Algorithm:
$ sort temp1 > temp2
$ rm temp1
Output:
Temporary File 2 with terms in sorted order by term:
Term Doc_id tf
ate 0 1
ate 1 2
ate 2 1
ate 3 1
cat 3 1
dog 0 1
dog 1 2
dry 2 1
duck 2 1
quickly 0 1
quickly 2 2
Pass III: Goal: Process Temporary 2 one line at a time to create the dict and post files.
Algorithm:
numdocs = 0;
start = 0;
read a line of the temporary file from Pass II
if term == prev_term
//it is another posting for the same term
numdocs++
add doc_id, tf to linked list of postings for that term
else
// you have all the postings in the list for the term
calc idf
write dict entry for the term (word, numdocs, start)
loop over list
write post entry (doc_id, tf OR rtf*idf)
start++
// handle first posting for new term
free postings list;
numdocs = 1;
add doc_id, tf to linked list of postings for that term;
Pros:
Low memory use
Cons:
Sorted dictionary file – slow for query processing
2 sets of temporary files – slow for indexing
This inverts 5 GB in 20 hours using 40 MB memory and 8 GB of for temporary files.
Tags: files init, temporary files, needed, memory, memorybased, indexing, temporary, requires, files
- SECTION 23 51 00 OR 23 35 00 PART1
- REFERAT FRA GENERALFORSAMLINGEN NORSK ORTOPEDISK FORENING HOLMENKOLLEN PARK HOTELL
- 0 PLAN MOT DISKRIMINERING OCH KRÄNKANDE BEHANDLING FÖR BRÅLANDA
- NATIONAL PLANNING AUTHORITY NOTICE OF EXPRESSION OF INTEREST FOR
- FIELD TRIPS THE DISTRICT HAS DEVELOPED A POLICY
- POSEŁ ADAM SZEJNFELD W 2010 ROKU SPRAWOZDANIE Z DZIAŁALNOŚCI
- ZAKON O IZMJENAMA I DOPUNAMA ZAKONA O ZAŠTITI NA
- BYLAWS DAHLONEGA DOWNTOWN DEVELOPMENT AUTHORITY DAHLONEGA GEORGIA ARTICLE I
- UN PUEBLO DE LA SIERRA DE HUELVA ÉRASE UNA
- MENTORING AND INDUCTION QUOTES “YOU CAN’T MEASURE SUCCESS IF
- CANCIÓN DE LOS DEDOS AB 103 “ESTE DEDICO PIDE
- CONSEJERÍA DE EDUCACIÓN DELEGACIÓN PROVINCIAL DE MÁLAGA CEIP MANZANO
- GUÍA DE EJERCICIOS DE COMPRENSIÓN LECTORA INFERENCIAL LAS PREGUNTAS
- B UKU PEDOMAN AKADEMIK PROGRAM STUDI TEKNIK INFORMATIKA UNIVERSITAS
- LINE OF CREDIT NOTE 50000000 AS OF AUGUST 26
- FEBRUARY 11 LECTURE GENERAL INFORMATION JERRY MARTY IS “FACILITIES
- LUIS FERNANDO GALLEGO RODRÍGUEZ (SECRETARIO DEL GRUPO MUNICIPAL PSOE)
- HOUSING COOPERATIVES AN OPPORTUNITY TO EXPAND HOMEOWNERSHIP FOR MODERATE
- MAGD STUDY PROGRAMS LISTED BELOW ARE MASTERSHIP STUDY
- TLAČOVÁ SPRÁVA STRANA 3 Z 3 UŽ TENTO TÝŽDEŇ
- SPONSORED BY CLASSIC HITS NEWSTALK ZB MASTERPET
- SAYVILLE PUBLIC SCHOOLS PARENT PORTALS ACCESS REQUEST FORM I
- P ROGRAM STUDI TEKNIK INFORMATIKA FAKULTAS TEKNIK UNIVERSITAS KRISTEN
- MARCA DA BOLLO EURO 1462 AL SIG SINDACO DEL
- 4752 §475—GENERAL CONSIDERATIONS FOR EVALUATING VISUAL IMPAIRMENT 4752 THE
- ESTADO DE SANTA CATARINA DECLARAÇÃO DE RELAÇÃO DE PARENTESCO
- FINANSE – WYCENA AKCJI MGR AGNIESZKA TYLEC ANALIZA PAPIERÓW
- OBRAZAC ZPO ZAHTJEV ZA ODGODU PLAĆANJA I OBROČNU OTPLATU
- BỘ TƯ PHÁP TỔNG CỤC THI HÀNH ÁN DÂN
- NOTA DE PRENSA FONTEIDE LANZA SU PRIMERA BOTELLA HECHA
FITNESS LIFTS RUBRIC THE BENCH PRESS KEYS TO THE
 A RCHITECTURAL AND ENGINEERING SPECIFICATIONS C ARD ACCESS MANAGEMENT
A RCHITECTURAL AND ENGINEERING SPECIFICATIONS C ARD ACCESS MANAGEMENT NOMINATION SPORT & PHYSICAL ACTIVITY IMPACT AWARD 2021 ACHPER
NOMINATION SPORT & PHYSICAL ACTIVITY IMPACT AWARD 2021 ACHPER APPLICATION FORM – ADMISSION TO THE LIST OF COUNSEL
APPLICATION FORM – ADMISSION TO THE LIST OF COUNSELCENTRAL EUROPEAN UNIVERSITY SUSTAINABILITY ADVISORY COMMITTEE FEBRUARY 25 2011
CHANNEL ACCESS PORTABLE SERVER REFERENCE GUIDE PHILIP STANLEY NOVEMBER
CONSULTORIAS TERMINOS DE REFERENCIA TÉRMINOS DE REFERENCIA PARA LA
POVZETEK REVIZIJSKEGA POROČILA O PRAVILNOSTI IZVAJANJA PODPROGRAMA SPODBUJANJE RAZVOJA
ILMO SEÑOR LOS ABAJO FIRMANTES D Y Dª
 HTTPWWWLOKOBRNOCZ POŘÁDÁ 42 ROČNÍK TRADIČNÍHO VÁNOČNÍHO TURNAJE V ŠACHU
HTTPWWWLOKOBRNOCZ POŘÁDÁ 42 ROČNÍK TRADIČNÍHO VÁNOČNÍHO TURNAJE V ŠACHU POSLANICA MLADIM OB 31 MAJU – SVETOVNEM DNEVU BREZ
POSLANICA MLADIM OB 31 MAJU – SVETOVNEM DNEVU BREZ7323 SEXUAL OFFENCES AGAINST CHILDREN (PRE1192) 1 OVERVIEW
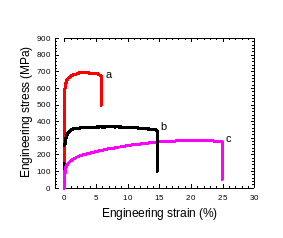 NANOSTRUCTURE AND RELATED MECHANICAL PROPERTIES OF AN ALMGSI ALLOY
NANOSTRUCTURE AND RELATED MECHANICAL PROPERTIES OF AN ALMGSI ALLOYYE CHEN EMAIL CHENYEKAUSTEDUSA DATE OF BIRTH 01081982 MAJOR
UČNA RAZPOREDITEV SNOVI V GIMNAZIJI GEOGRAFIJA 1 LETNIK
MYSŁOWICE DN ……………… SĄD REJONOWY W MYSŁOWICACH WYDZIAŁ III
 NAHC GOVERNMENT RELATIONS COMMITTEE FUNDING OPPORTUNITIES FOR HOUSING COOPERATIVES
NAHC GOVERNMENT RELATIONS COMMITTEE FUNDING OPPORTUNITIES FOR HOUSING COOPERATIVESSTAATLICHES STUDIENSEMINAR FÜR DAS LEHRAMT AN GYMNASIEN 55543 BAD
KITÖLTÉSI SEGÉDLET A MEGFELELÉSI NYILATKOZATHOZ 1 MI A JOGSZABÁLYOKNAK
EDUCATIONAL PLANNING TABLE – LIVE TO VIEW A SAMPLE
